Hi,
I have an object detection dataset with RGB images and annotations in Json. I use a custom DataLoader class to read the images and the labels. One issue that I’m facing is that I would like to skip images when training my model if/when labels don’t contain certain objects.
For example, If one image doesn’t contain any target labels belonging to the class ‘Cars’, I would like to skip them. When parsing my Json annotation, I tried checking for labels that don’t contain the class ‘Cars’ and returned None. Subsequently, I used a collate function to filter the None but unfortunately, It is not working. Any suggestions? Thanks.
import torch
from torch.utils.data.dataset import Dataset
import json
import os
from PIL import Image
from torchvision import transforms
#import cv2
import numpy as np
general_classes = {
# Cars
"Toyota Corolla" : 0,
"VW Golf" : 0,
"VW Beetle" : 0,
# Motor-cycles
"Harley Davidson" : 1,
"Yamaha YZF-R6" : 1,
}
car_classes={
"Toyota Corolla" : 0,
"VW Golf" : 0,
"VW Beetle" : 0
}
def get_transform(train):
transforms = []
# converts the image, a PIL image, into a PyTorch Tensor
transforms.append(T.ToTensor())
if train:
# during training, randomly flip the training images
# and ground-truth for data augmentation
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
def my_collate(batch):
batch = list(filter(lambda x: x is not None, batch))
return torch.utils.data.dataloader.default_collate(batch)
class FilteredDataset(Dataset):
# The dataloader will skip the image and corresponding labels based on the dictionary 'car_classes'
def __init__(self, data_dir, transforms):
self.data_dir = data_dir
img_folder_list = os.listdir(self.data_dir)
self.transforms = transforms
imgs_list = []
json_list = []
self.filter_count=0
self.filtered_label_list=[]
for img_path in img_folder_list:
#img_full_path = self.data_dir + img_path
img_full_path=os.path.join(self.data_dir,img_path)
json_file = os.path.join(img_full_path, 'annotations-of-my-images.json')
img_file = os.path.join(img_full_path, 'Image-Name.png')
json_list.append(json_file)
imgs_list.append(img_file)
self.imgs = imgs_list
self.annotations = json_list
total_count=0
for one_annotation in self.annotations:
filtered_obj_id=[]
with open(one_annotation) as f:
img_annotations = json.load(f)
parts_list = img_annotations['regions']
for part in parts_list:
current_obj_id = part['tags'][0] # bbox label
check_obj_id = general_classes[current_obj_id]
if(check_obj_id==0):
subclass_id=car_classes[current_obj_id]
filtered_obj_id.append(subclass_id)
total_count=total_count+1
if(len(filtered_obj_id)>0):
self.filter_count=self.filter_count+1
self.filtered_label_list.append(one_annotation)
print("The total number of the objects in all images: ",total_count)
# get one image and the bboxes,img_id, labels of parts, etc in the image as target.
def __getitem__(self, idx):
img_path = self.imgs[idx]
image_id = torch.tensor([idx])
with open(self.annotations[idx]) as f:
img_annotations = json.load(f)
parts_list = img_annotations['regions']
obj_ids = []
boxes = []
for part in parts_list:
obj_id = part['tags'][0]
check_obj_id = general_classes[obj_id]
if(check_obj_id==0):
obj_id=car_classes[obj_id]
obj_ids.append(obj_id)
#print("---------------------------------------------------")
if(len(obj_ids)>0):
img = Image.open(img_path).convert("RGB")
labels = torch.as_tensor(obj_ids, dtype = torch.int64)
target = {}
target['labels'] = labels
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
else:
return None
def __len__(self):
return len(self.filtered_label_list)
train_data_path = "path-to-my-annotation"
# Generators
train_dataset = FilteredDataset(train_data_path,get_transform(train=True))
print("Total files in the train_dataset: ",len(train_dataset))
#print("The first instance in the train dataset : ",train_dataset[0])
#training_generator = torch.utils.data.DataLoader(train_dataset)
training_generator = torch.utils.data.DataLoader(train_dataset,collate_fn=my_collate)
print("\n\n Iterator in action! ")
print("---------------------------------------------------------")
count=0
for img,target in training_generator:
#print("The img name : ",img[0])
count=count+1
print("target name : ",target)
print("count : ",count)
print("**************************************************")
However, I get the following error,
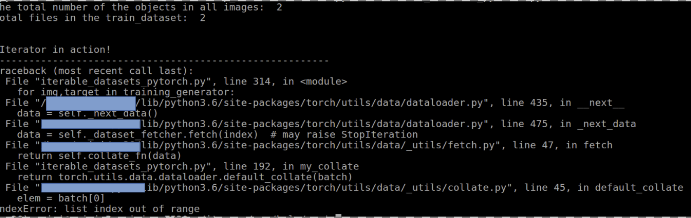
Could anyone please suggest a way to skip the images that do not contain a particular categorical label?