Hello Everyone,
I am new to pyotorch and learning quickly.
I’m trying to train a DeiT from scratch. Obeying the strategy in the original paper, I use a batch size of 256 and 8Gpus(2080Ti) parallel training.
According to SwinV2, I try to move LayerNorm beind the residual module(attention or MLP) in the original DeiT, as showed below.
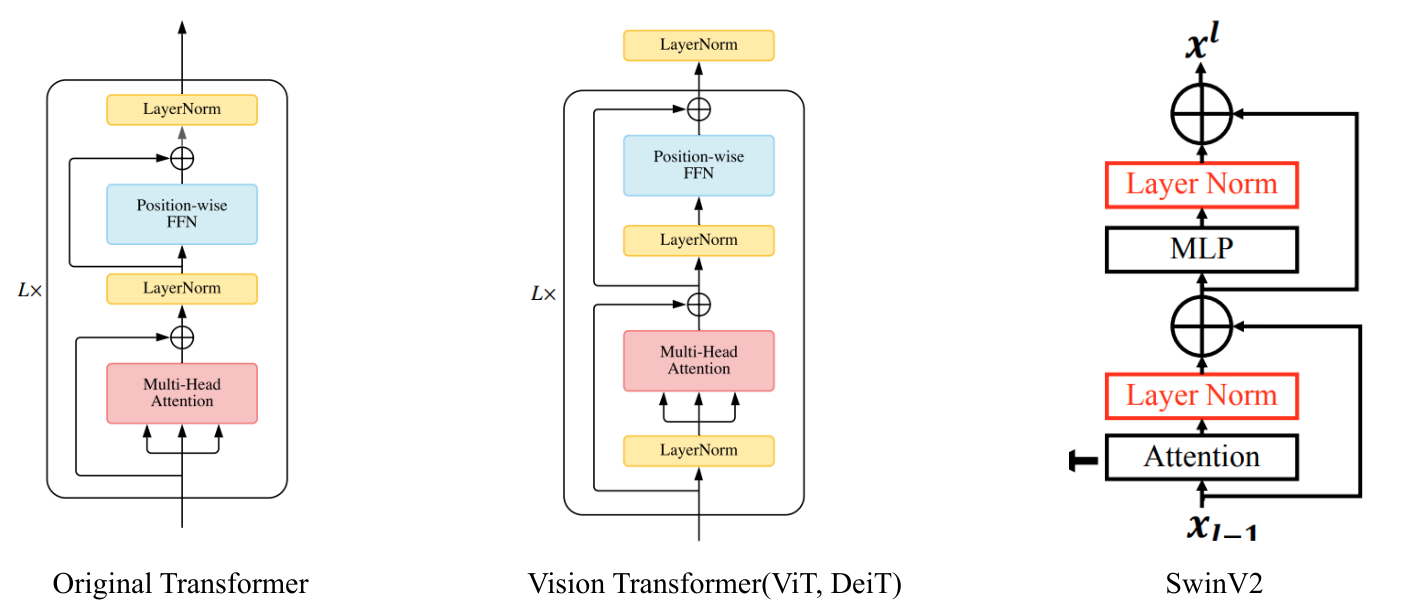
Unfortunately I didn’t get a more stable training as SwinV2 said, but resulted in ‘Loss is NaN’, after about 3 epochs of training. I’ve set the warmup and learning rate same as DeiT.
I don’t know how to debug in DistributedDataParallel mode. Could somebody give some suggestions? Or could somebody give some insights in training Vision Transformer?
Thanks a lot in advance for help.