I have a validation loss of .02 during training. I see this in tensorboard.
After, I load up the model’s checkpoint. I set all parameters to have 0 gradient. Then I run my training script again and comment out the backward pass:
with self.timers.record("grad"):
self.optimizer.zero_grad()
if self.use_fp16:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
This is the plot I see:
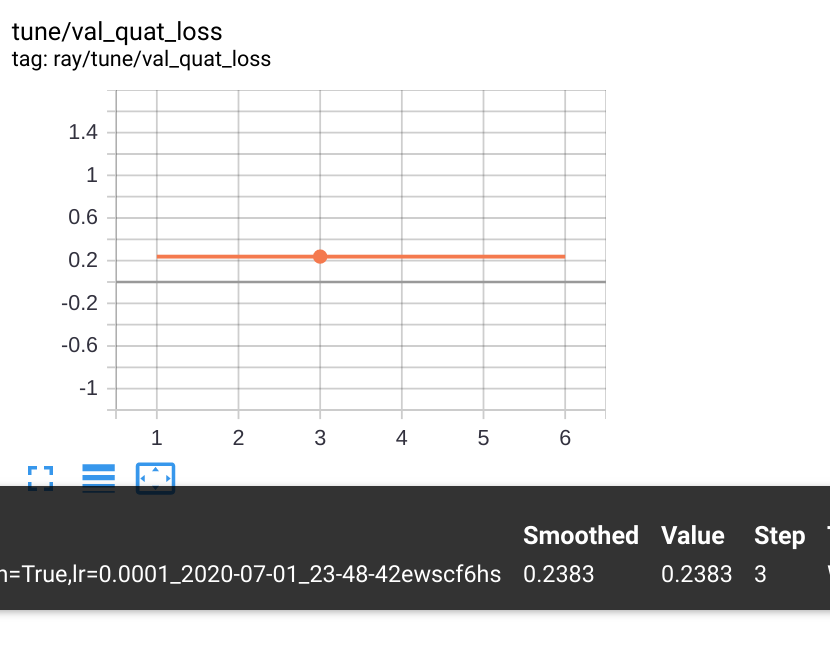
The error is much higher, and also constant (I would expect variation from the minibatches).
Any clue what’s happening?