I used following class to define RNN
class RNN_Model(torch.nn.Module):
def __init__(self, input_size, rnn_hidden_size, output_size):
super(RNN_Model, self).__init__()
self.rnn = torch.nn.RNN(input_size, rnn_hidden_size,
num_layers=1, nonlinearity='relu',
batch_first=True)
self.h_0 = self.initialize_hidden(rnn_hidden_size)
self.linear = torch.nn.Linear(rnn_hidden_size, output_size)
self.sigmoid= torch.nn.Sigmoid()
def forward(self, x):
x = x.unsqueeze(0)
self.rnn.flatten_parameters()
out, self.h_0 = self.rnn(x, self.h_0)
out = self.linear(out)
out= self.sigmoid(out)
return out
def initialize_hidden(self, rnn_hidden_size):
# n_layers * n_directions, batch_size, rnn_hidden_size
return Variable(torch.randn(1,1,rnn_hidden_size),
requires_grad=True)
and here how I am training
# # training logic
def train(model,x,y,criterion,optimizer):
# '''
# train NN
# '''
model.train()
y_pred = model(x)
loss = criterion(y_pred[0], y)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
out=0
if y_pred[[[0]]] >= 0.5:
out=1
return loss.item(),out
# dict_outs['loss_valid_net1']=loss_valid_net1
dtype = torch.float
device = torch.device("cpu")
input_dim = 2
hidden_dim = 16
output_dim = 1
layer_dim = 1
model_one = RNN_Model(input_dim, hidden_dim, output_dim).to(device)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model_one.parameters(),lr=1e-2, momentum=0.9, nesterov=True)
loss_list=[]
for j in range(50):
# generate a simple addition problem (a + b = c)
a_int = np.random.randint(largest_number/2) # int version
a = int2binary[a_int] # binary encoding
b_int = np.random.randint(largest_number/2) # int version
b = int2binary[b_int] # binary encoding
# true answer
c_int = a_int + b_int
c = int2binary[c_int]
# print(a_int,b_int,c_int)
# where we'll store our best guess (binary encoded)
d = np.zeros_like(c)
output=''
for position in range(binary_dim):
# generate input and output
X = np.array([[a[binary_dim - position - 1],b[binary_dim - position - 1]]])
y = np.array([[c[binary_dim - position - 1]]]).T
# print(X.shape,y.shape)
x_train = torch.tensor(torch.from_numpy(X),device=device,dtype=dtype)
y_train = torch.tensor(torch.from_numpy(y),device=device,dtype=dtype)
loss=train(model_one,x_train,y_train,criterion,optimizer)
output+=str(loss[1])
loss_list.append(loss[0])
out=0;out_str=''
for index,x in enumerate(reversed(output)):
out_str+=x
out += int(x)*pow(2,index)
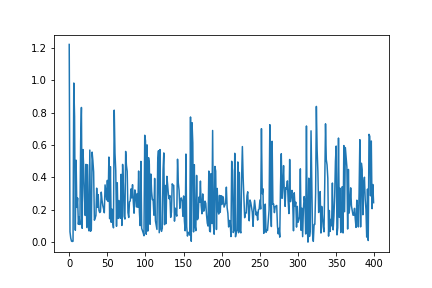
My loss values are oscillating, I am not able to understand why?