Hi, i want to define anactivation function with 2 trainable parameters, k and c, which define the function.
I want my neural net to calibrate those parameters aswell during the training procedure. Do you have an idea on how i can manage to do that in few lines? I am really new on pytorch.
Here is my code for the moment, with fixed values of k and c as you can see…
is it a right way to call the newly created activation ?
am I supposed to perform somewhere “myTanh.zero_grad()”, “myTanh.eval()” ? or is it already taken into account when i do it with the entire net: netG = Generator().to(device) ; netG.zero_grad()
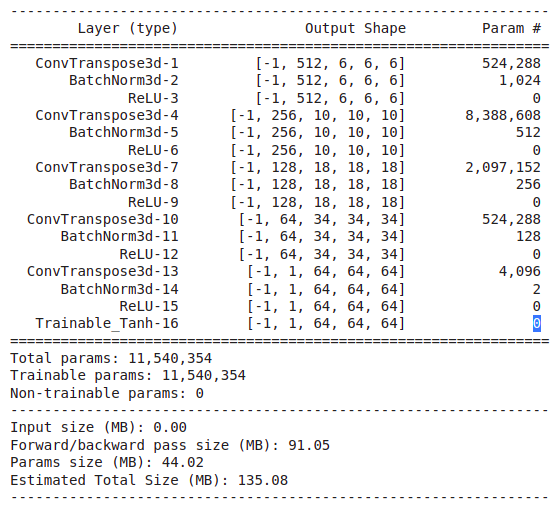
when i do a torch summary of my final network, i don’t observe 2 more trainable parameters. I have exactly the same number of trainabe parameters as before. It is strange because normally i introduced 2 additionnal parameters. Please could you tell me where i am wrong ?
No, since you are re-initializing the trainable activation module in each forward pass (so it won’t actually be trained at all).
Treat this module as any other layer, initialize it in your Generator.__init__ method, and use it in the forward:
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.myTanh = Trainable_Tanh()
...
def forward(self, x):
...
result = myTanh(t_c_5)
...
If you register Trainable_Tanh properly in the Generator.__init__ method, its gradients will be zeroed out from the parent module and also its training flag will be changed from the parent. As mentioned before: just treat it as any other layer such as nn.Linear.
I guess because you are never registering it as mentioned in the previous points.
Here is the torch summary, and i see that the tanh layer don’t have the 2 additional trainable parameters… do you have an idea on how to fix my code please ?