I am trying the Object Detection Finetuing tutorial, which is very nice, smooth and helpful. I think there is a little bug in the labels, as they should mimic " labels (Int64Tensor[N]) : the label for each bounding box", or more plausibly, " labels (Int64Tensor[N]) : the label for each object". Clearly, the code works well with the Fudan dataset as it only has one object, ie person. If I am correct, then
Now I think what I am proposing is also incorrect, as labels should contain, probably, the object_id or label_id and the number times each object is repeated in the mask. For example, having two classes with 3 objects of the first class and 5 object of the second class, one might need to use the following structure (background is dropped of course).
[1 1 1; 2 2 2 2 2]
I guess such labeling structure is used for evaluation using pycocotools. I have tried both the original form and the one I posted above and they both work, but I am concerned that they are both incorrect for my specific problem having 60 difference classes.
Hence, before reporting an issue, I am going to edit the title of the question and see if someone else has come up with an idea of how to deal with the labels.
Hi
Have you solved this issue?
Can’t uderstand how data should look like if I have several objects for one class
boxes (FloatTensor[N, 4]): the ground-truth boxes in [x1, y1, x2,y2] format, with values of x between 0 and W and values of y between 0 and H
labels (Int64Tensor[N]): the class label for each ground-truth box
So the model should take N boxes of size 4, where N is the number of classes, I can’t understand how to pass several objects of one class. Please help
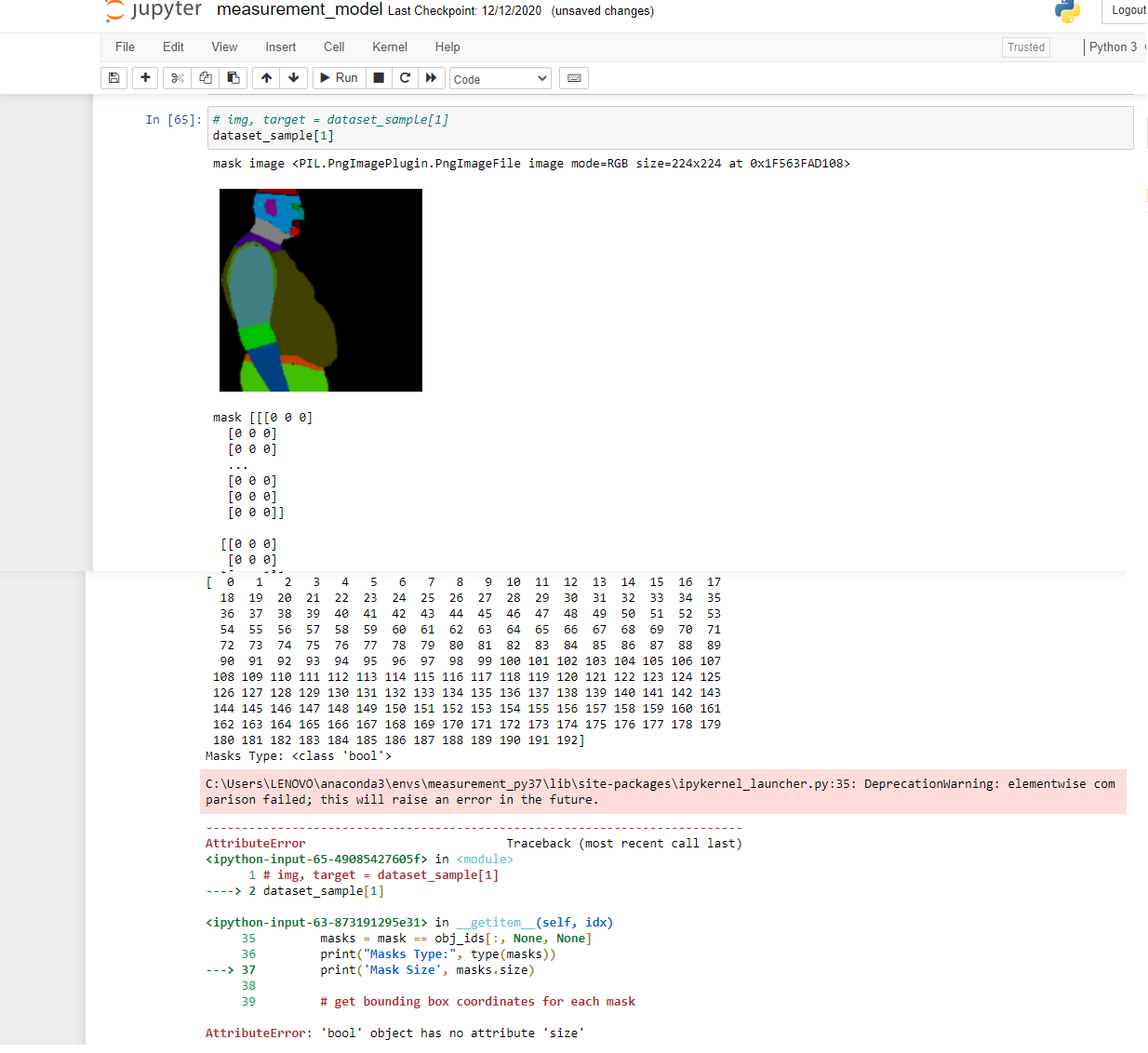
# instances are encoded as different colors
obj_ids = np.unique(mask)[1:] # first id is the background, so remove it
masks = mask == obj_ids[:, None, None] # split the color-encoded mask into a set of binary masks
# get bounding box coordinates for each mask
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
# convert everything into torch.Tensor
boxes = torch.as_tensor(boxes, dtype=torch.float32)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
Thanks so much. I gonna try this now and let you know. Thanks again. Between I have about 38 classes excluding the background(black) and not all images have all 38 classes in them. Does still work?
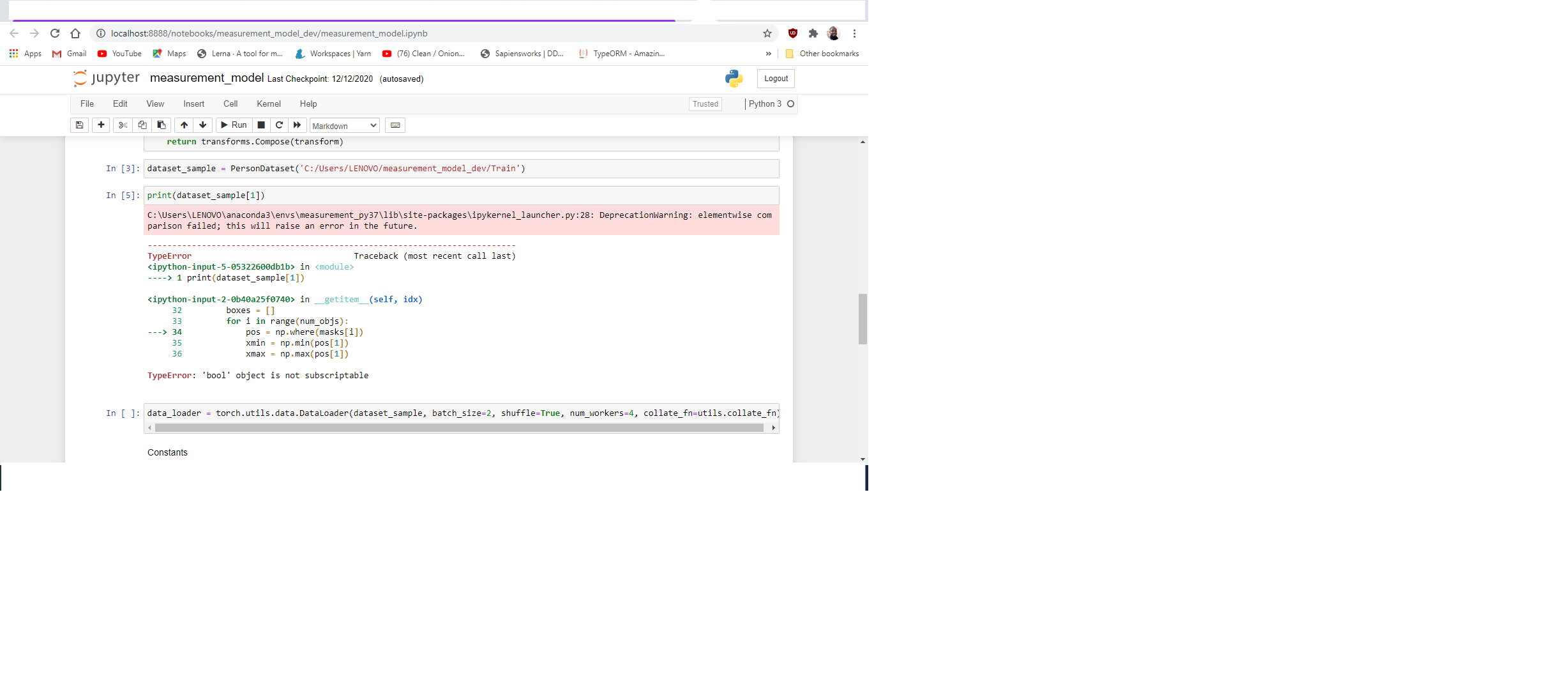
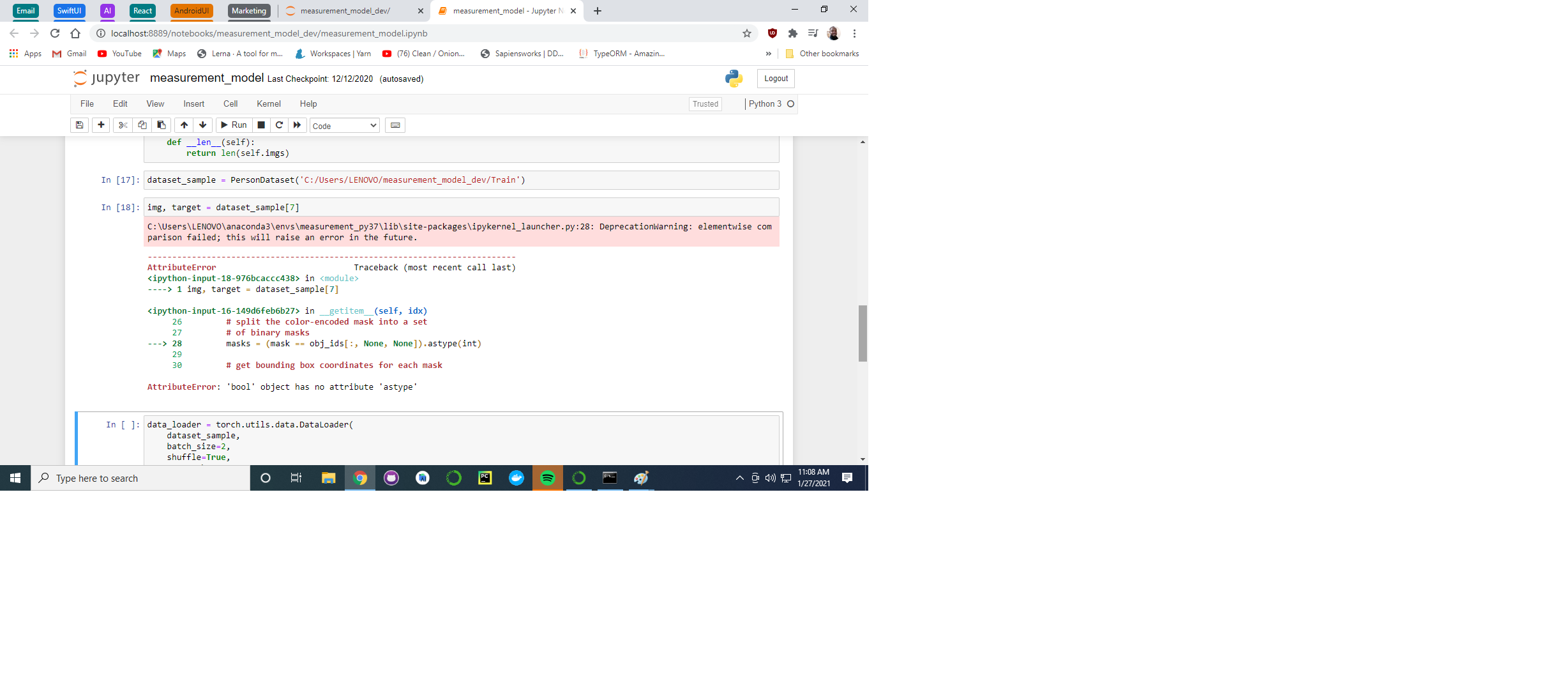
is to finish the entire code and see if I can train the model, maybe I am thinking it too much by trying to see what the data is inside the return from:
img, target = dataset_sample[7].
Any suggestions? or help will be appreciated.
And I do really appreciate the all time taken to reply and help.
Not sure what and how 're you doing it. If you have a png image, you can get the mask from the alpha channel, then, convert it to a numpy array. Something like:
mask = image.getchannel('A') # getting the mask from the alpha channel (png image), 255 for foreground, 0 otherwise
mask = numpy.asarray(mask)
mask = np.asarray(mask, dtype= 'int') # or uint8
mask=mask/255 # 0 to 1 scale
Hey,
Were you trying to do multi class semantic segmentation or instance segmentation. If you were doing semantic segmentation, could you please explain what is the purpose of getting the bounding boxes!
I am using detectron2 for model training with MaskRcnn and it needs the data in coco-json file so I also want to add images for training without any ground truth to reduce the false detection so how can I do it?
currently I am using labelme tool for image labelling