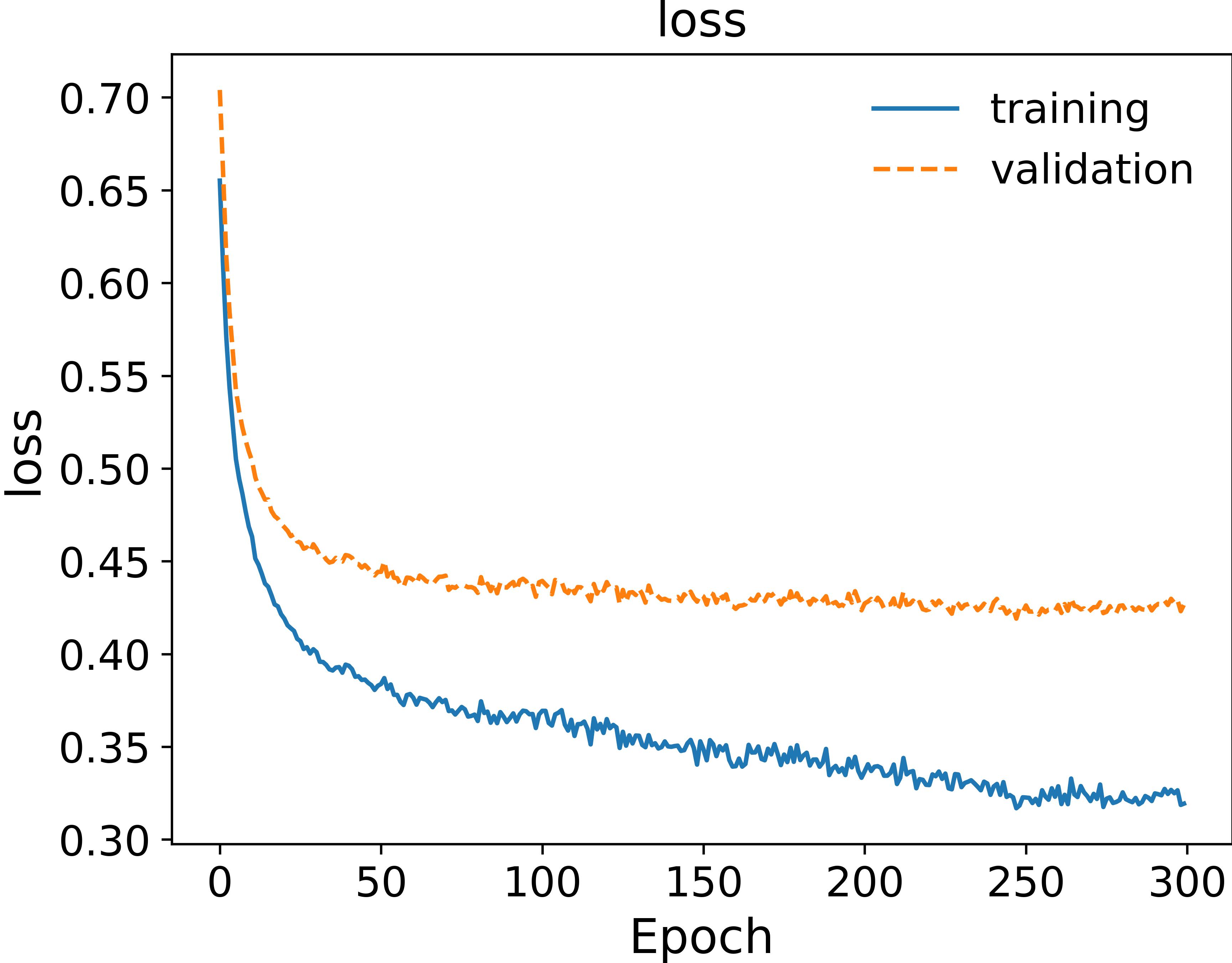
I am using Transformer for time series regression (not forecasting). My input data has the structure [batch, seq_size, embedding_dim], and my output structure is [batch, seq_size, 1]. But the result of the model is always overfitting and is worse than the LSTM. I don’t want to include the target information in the decoder. Can anyone tell me how to design the decoder?
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self, d_input, n_head, d_model, n_layer):
super(Transformer, self).__init__()
self.enc_position_embedding = self.data_position_embedding(c_in=d_input, d_model=d_model)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=n_head)
self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=n_layer)
self.project = nn.Linear(d_model, 1)
def forward(self, x):
x_emb = self.enc_embedding(x)
enc = self.encoder(x_emb)
dec = enc
output = self.project(dec)
return output
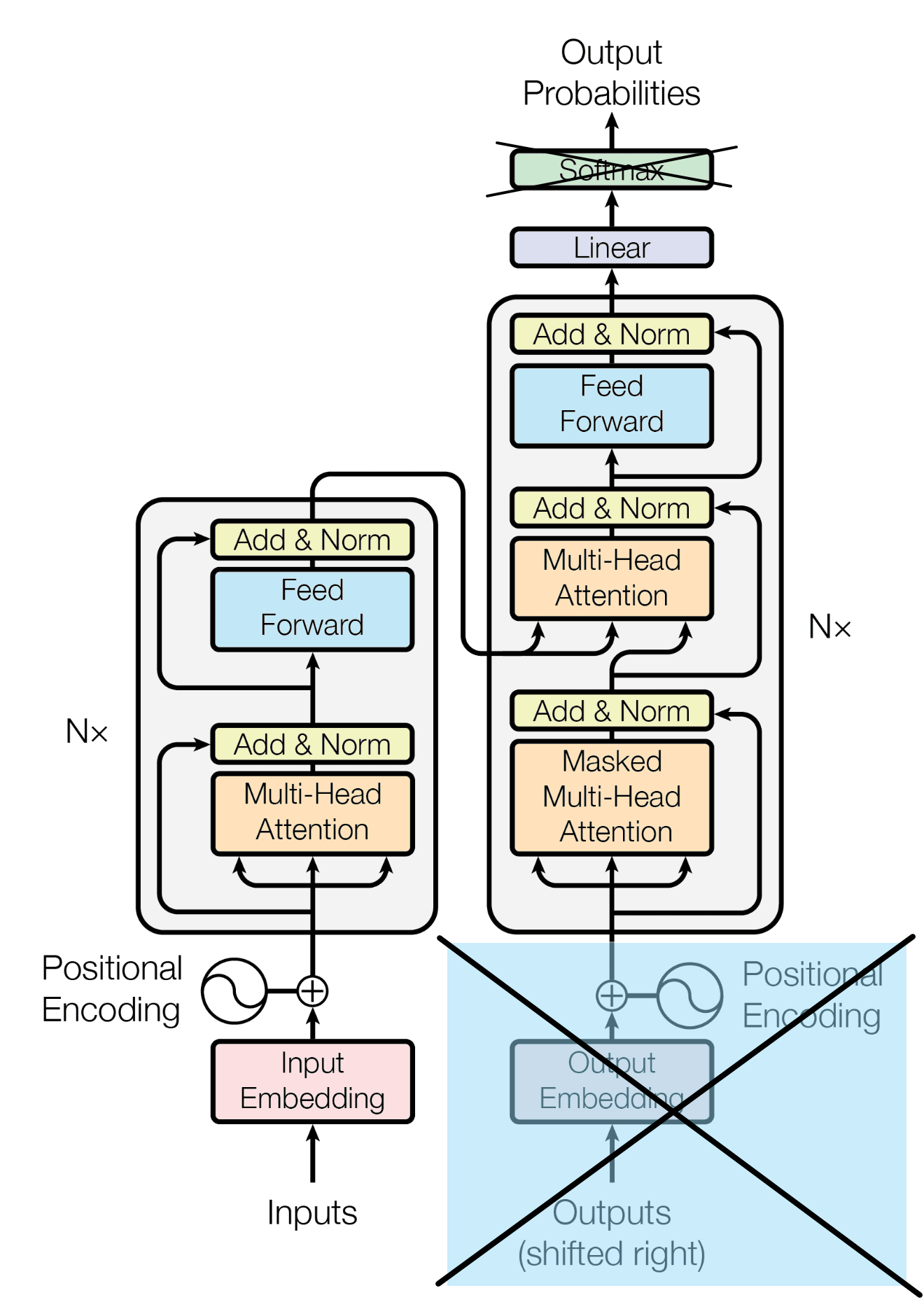
Structure:
loss curve: