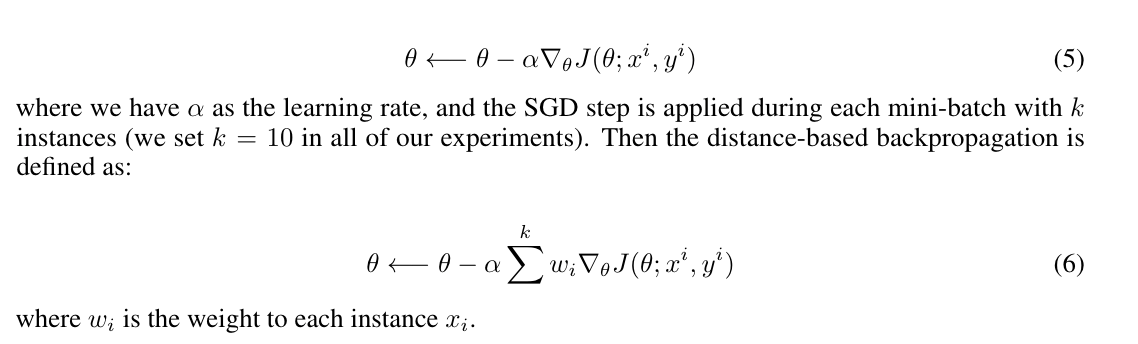Hi,
I want to implement a ‘weighted’ version of gradient descent like this:
for each data point in that batch, I want to calculate the gradient, and a weight (I have this already) and then will do the descent together.
However, I went through some posts, did not really find useful info. Can someone help?
Thanks.
After doing the loss.backward() (which will calculate the grads), but before optimizer.step() each parameter has a .grad attribute (which should be not None for updated parameters) and you could manipulate the gradients there.
loss.backward()
optimizer.step()
.grad
Thanks for the solution!
However, it seems can not work to an individual sample. What I need is: grad_1, grad_2, grad_3,…
Where they are gradients for each sample in that batch.