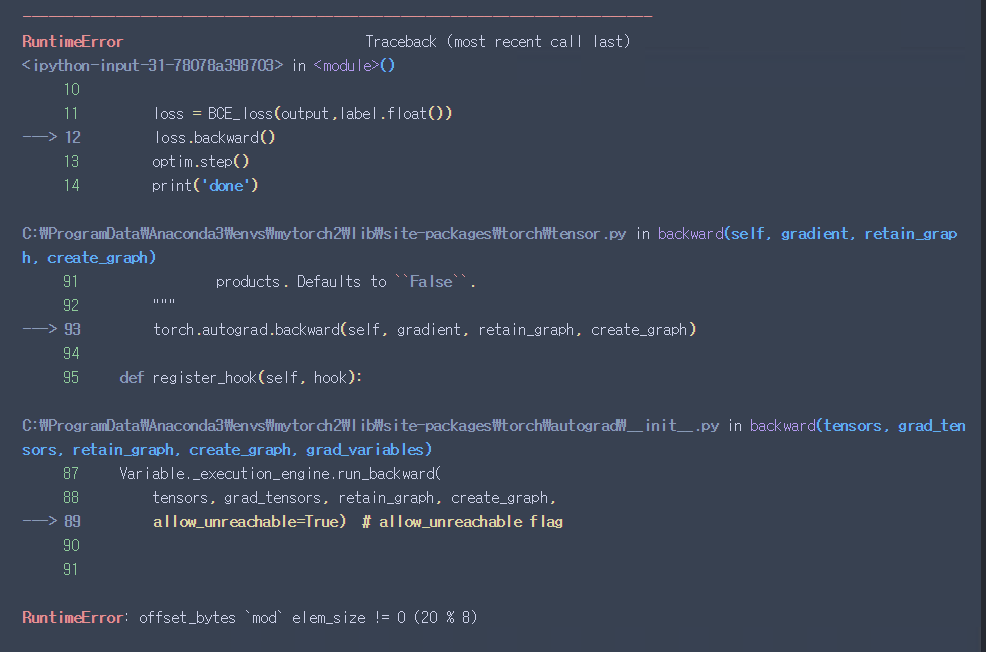
Hi, thank for giving attention to my question.
A multimodel class has three independent model(GRU1, GRU2, GRU3) and all these outputs are concatenated then the last single neural network was attached to an ensemble. the code is like below.
But there might be some problems. Although the value of loss was calculated well. At the stage of loss.backward, it raised an error. Is there any solution to backprop multi models? I think torch cannot track tensor to the start point. Where should I fix the code? Is there any example like this model?
Thanks for spending you time to read my question.
class MultiModels (torch.nn.Module):
def __init__(self,batchsize,hidden_size,hidden_n,dropout=0.5):
super(GRU,self).__init__()
self.batchsize = batchsize
self.hidden_size = hidden_size
self.hidden_n = hidden_n
self.dropout = dropout
# GRU(feature 수,output_size,num_layer)
self.GRU1 = torch.nn.GRU(3,hidden_size,hidden_n,batch_first=True)
self.GRU2 = torch.nn.GRU(2,hidden_size,hidden_n,batch_first=True)
self.GRU3 = torch.nn.GRU(2,hidden_size,hidden_n,batch_first=True)
self.ensemble_layer1 = torch.nn.Linear(3*5,7)
self.ensemble_layer2 = torch.nn.Linear(7,1)
def forward(self,input,hidden):
out1,hidden1 = self.GRU1(input,hidden.clone())
out1 = out1.float()
out2,hidden2 = self.GRU2(input[:,:,[0,1]],hidden.clone())
out2 = out2.float()
out3,hidden3 = self.GRU3(input[:,:,[1,2]],hidden.clone())
out3 = out3.float()
total_out = torch.cat((out1[:,-1,:],out2[:,-1,:],out3[:,-1,:]),1)
out = self.ensemble_layer1(total_out)
out = self.ensemble_layer2(out)
out = out.view(self.batchsize,-1)
return out
def init_hidden(self):
hidden = torch.Tensor(torch.zeros(self.hidden_n,self.batchsize,self.hidden_size)).cuda()
return hidden
model = MultiModels(16,5,2)
loss_f = BCEwithLogitLoss()
optim = Adam(model.parameters(),lr=0.001)
------training session------
optim.zero_grad()
hidden = model.init_hidden()
pred = model(input,hidden)
loss = loss_f(pred,label)
loss.backward() # Error!