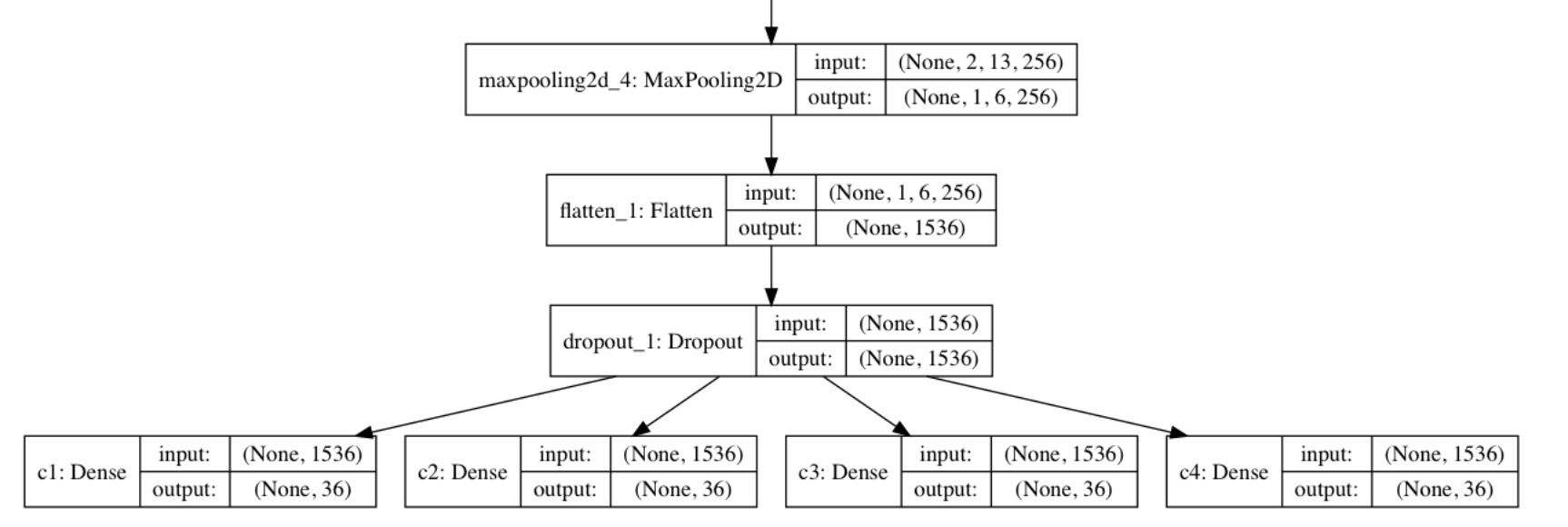
If you put your dropout_1 output into the 4 Linear layers (probably with 4 outputs, not 36) you can then calculate the losses individually and add them up to form a total loss.
Using that for gradient descent will do the right thing.
I use nn.CrossEntropyLoss() as my criterion function, and the label as follow:
And code about loss is as follow:
# forward
outputs = model(inputs)
loss = 0
for lx in range(len(outputs)):
tmp_loss = criterion(outputs[lx], labels[:, lx])
loss += tmp_loss
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
The main problem here is how to add the losses of labels I have, because 0 stands for No Label and Invisible, it is not easy to differ.
I would recommend using a mask (1 label, 0 no label) and labels 0…3 (doesn’t matter what if the mask is 0). Then you can take the loss with reduce=False and multiply with the mask, sum over classes and take the mean over the batch.
In terms of your code above (CrossEntropyLoss seems good to me unless you have a reason not to use it):
criterion = CrossEntropyLoss(reduce=False)
...
loss = 0
for lx in range(len(outputs)):
loss = loss + (mask[:,lx]*criterion(outputs[lx], labels[:, lx])).mean()
(So the loss with reduce=False reduces over the classes, giving you a float vector of batch_size, mask should be a float of shape batch_size x tasks).
Looking at the CrossEntropyLoss documentation, I also found an alternative to using the mask: If you put -100 in your label where you don’t have one, you can use the ignore_index feature and it’ll do the right thing for you without needing changes to your code above.
you can use label -1 index no label,
set criterion = nn.CrossEntropyLoss(ignore_index=-1, reduction=“mean”)
I want to know, for multi-task, the label is a label list, so how to create your Dataset, Could you please show me your defined Dataset? Thank you very much~
Shameless plug: I wrote a little helper library that makes it a little easier to do multi-task learning: torchMTL. It should work for your example and makes it easy to combine the losses while keeping control over the training loop. I thought it might be of interest for people who are running into similar issues.