Since very recently, inception_v3 is available in torchvision.models and getting it is as simple as typing model = models.inception_v3(pretrained=True)
Since the model was pretrained on ImageNet it has 1000 output classes which I wanted to change to 2 for my binary classifier - so I created the following head:
from collections import OrderedDict
head = nn.Sequential(OrderedDict([
('fc1', nn.Linear(2048, 1024)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(1024, 512)),
('relu2', nn.ReLU()),
('fc3', nn.Linear(512, 128)),
('relu3', nn.ReLU()),
('fc4', nn.Linear(128, 32)),
('relu4', nn.ReLU()),
('fc5', nn.Linear(32, 2)),
('output', nn.LogSoftmax(dim=1))
]))
My question is regarding how to add this head. If I was using restnet54, this would be as simple as model.fc = head but in the case of inception_v3 I have realized there is what it looks like as two output layers:
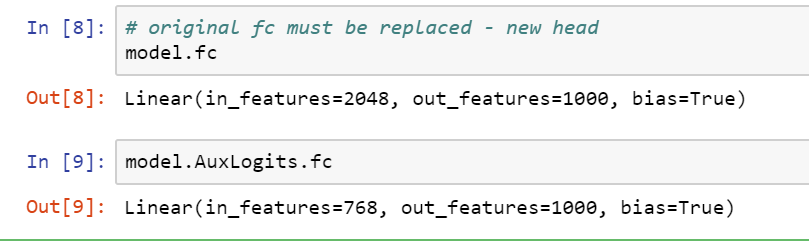
and by doing model(inputs) I also get and InceptionOutputs(logits=tensor([[-0.8333, -0.5702] [...], device='cuda:0', grad_fn=<LogSoftmaxBackward>), aux_logits=tensor([[ 1.0039, 2.4251] [...]
Do I need to change both heads? What is the difference between logits and aux_logits. I see the term ‘logits’ being used very often but I struggle to make sense of it (i.e. I understand the difference between scores and probs after a softmax, not sure where logits and aux_logits fit in this schema).
This would affect the whole training process, i.e. it can no longer be only optimizer = optim.Adam(model.fc.parameters(), lr=0.001)
 but your link and explanation was super useful! Thanks again.
but your link and explanation was super useful! Thanks again.