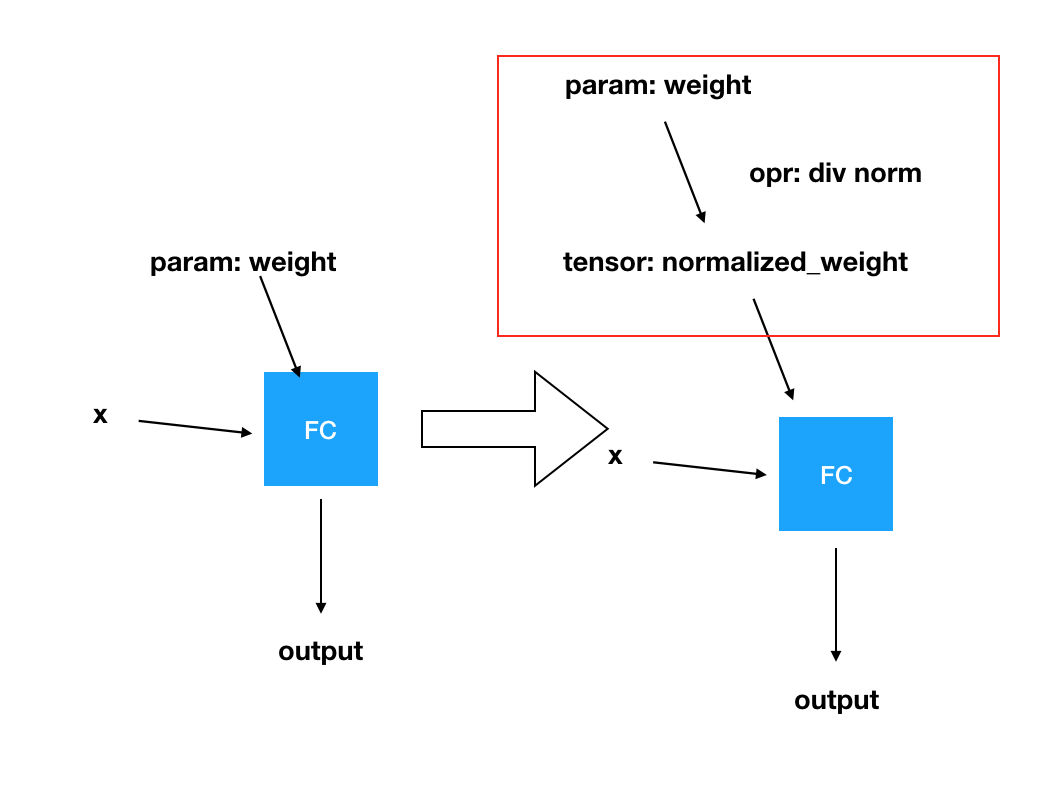
Many loss functions in face recognition will norm feature or norm weight before calculate softmax loss, such as normface(https://arxiv.org/abs/1704.06369), L2-softmax(https://arxiv.org/abs/1703.09507) and so on.
I’d like to know how to norm weight in the last classification layer.
self.feature = torch.nn.Linear(7*7*64, 2) # Feature extract layer
self.pred = torch.nn.Linear(2, 10, bias=False) # Classification layer
I want to replace the weight parameter in self.pred module with a normalized one.
In another word, I want to replace weight in-place, like this:
self.pred.weight = self.pred.weight / torch.norm(self.pred.weight, dim=1, keepdim=True)
When I trying to do this, there is something wrong:
TypeError: cannot assign 'torch.FloatTensor' as parameter 'weight' (torch.nn.Parameter or None expected)
I am new comer to pytorch, I don’t know what is the standard way to handle this. Thanks a lot!
Here is the whole code:
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.backbone = torch.nn.Sequential(
torch.nn.Conv2d(1, 8, kernel_size=7, stride=1, padding=3),
# 28 * 28
torch.nn.Conv2d(8, 16, kernel_size=5, stride=1, padding=2),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2, kernel_size=2),
# 14 * 14
torch.nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2, kernel_size=2),
# 7 * 7
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
)
self.feature = torch.nn.Linear(7*7*64, 2) # Feature extract layer
self.pred = torch.nn.Linear(2, 10, bias=False) # Classification layer
## something wrong here
self.pred.weight = self.pred.weight / torch.norm(self.pred.weight, dim=1, keepdim=True)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight)
elif isinstance(m, torch.nn.BatchNorm2d):
torch.nn.init.constant_(m.weight, 1)
torch.nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.backbone(x)
x = x.view(-1, 7 * 7 * 64)
x = self.feature(x)
x = self.pred(x)
return x
Besides,
- if I don’t want to use
viewfunction in forward function, how to deal with it in__init__function? - how I can extract the weight, which is before normalization and after normalization?
- If I want to norm feature which is the output feature map in the last two fc layer in
__init__function, how to do it?
Thanks a lot!