There is a problem that has bothered me for quite a long time. Assume we are minimizing a loss function parameterized by , on samples using SGD, where M is the mini-batch size. Since the PyTorch autograd can only be implicitly created for scalar outputs, I am wondering if there is any efficient way to compute the gradient for each sample, i.e., , without setting the batch size equals to 1 and compute in a for loop (which is too slow)?
Thanks so much for your reply! If the loss is set to be a non-scaler, i.e., the sample loss:
loss = F.cross_entropy(predictions, results, reduction='none')
loss.backward(gradient=torch.ones_like(loss))
I’m still confused about how to get the gradient on each sample, if I run the following code:
for params in model.parameters():
print(params.grad)
I expect to get B times the number of tensors returned in the mini-batch case, since there should be an individual result for each sample.
In addition, it would be very helpful if you could point me to the document of Tensor.backward() function (if any), so that I can learn more on this. Thanks again!
For the params.grad, it is already the accumulated gradient of B samples.
But if you need to obtain the gradient on each sample, you can set
X.retain_grad() before backward. And then through X.grad to get the gradient of loss on each sample.
Are you going to extend this to other popular layer types, e.g. ReLu and batchnorm? This would make it useful for most widely used architectures such as Resnets
It should work for those architectures as well. What’s missing is support for other layers with trainable parameters, (ie the multiheadattention layer)
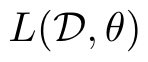 parameterized by
parameterized by 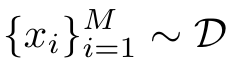 using SGD, where M is the mini-batch size. Since the PyTorch autograd can only be implicitly created for scalar outputs, I am wondering if there is any efficient way to compute the gradient for each sample, i.e.,
using SGD, where M is the mini-batch size. Since the PyTorch autograd can only be implicitly created for scalar outputs, I am wondering if there is any efficient way to compute the gradient for each sample, i.e., 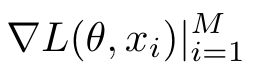 , without setting the batch size equals to 1 and compute in a for loop (which is too slow)?
, without setting the batch size equals to 1 and compute in a for loop (which is too slow)?