Hi,
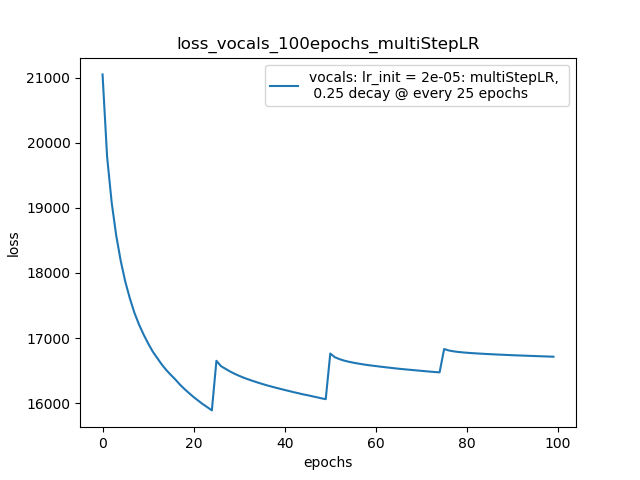
I’m training an AutoEncoder network with Adam optimizer (amsgrad=True). My loss decreases very rapidly initially but slowly it starts saturating.
How can I accelerate the learning to decrease my loss? A standard strategy is to decay the learning rate; but when I do this to Adam optimizer my loss jumps abruply.
I’m using pytorch’s scheduler.MultiStepLR() to decay my learning rate.
Below is my loss plot.