I have developed a script for DDP training following the Pytorch tutorials, and the vision/reference/classification/train.py. So my code is pretty similar to the original from the pytorch/vision.
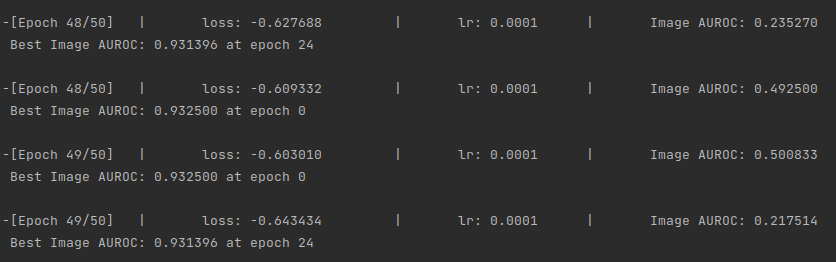
Training and evaluation work fine. However, I am concerned with the evaluation metric. However, I have two different metrics because I have two GPUs (in one unique node). This can be seen in the following image.
My dataset has 5000 images; each GPU evaluates half of the data. But the thing is to evaluate all the 5000 images in one unique model, trained in a distributed manner. I would like to have some guidelines on this. This is a straightforward version of my code for evaluation:
import torch
from sklearn.metrics import roc_auc_score
model.eval()
y_true = list()
y_score = list()
for x, y in dataloader_test:
x = x.to(args.device)
output = model(x)
y_true.extend(y.item()) # Binary values
y_score.extend(output.item()) # Some score predicted
image_auroc = roc_auc_score(y_true, y_score)
Let us suppose just the “y_true” variable. I want to have one unique list with the binaries from both GPUs. I added this code just before the last line,
The binary values are added because torch.distributed.all_reduce makes sum operations. What I want to do is to extend the y_true to have [y_true_from_gpu0, y_true_from_gpu1]. If this is achieved, I must replicate it with y_score to have one unique AUROC metric to have the evaluation done.
import torch
import os
rank = int(os.environ["RANK"]) # Rank of the current process in the job
world_size = int(os.environ["WORLD_SIZE"]) # Number of processes participating in the job
gpu = int(os.environ["LOCAL_RANK"]) # Rank of the current process in the local job
dist_url = 'env://'
torch.cuda.set_device(gpu)
torch.distributed.init_process_group(
backend='nccl', init_method=dist_url, world_size=world_size, rank=rank
)
torch.distributed.barrier()
tensor = torch.arange(5, device=gpu)
torch.distributed.barrier()
print(tensor) # tensor([0, 1, 2, 3, 4], device='cuda:1')tensor([0, 1, 2, 3, 4], device='cuda:0')
torch.distributed.all_reduce(tensor)
print(tensor) # tensor([0, 2, 4, 6, 8], device='cuda:0')tensor([0, 2, 4, 6, 8], device='cuda:1')
# However, I want to have [0, 1, 2, 3, 4, 0, 1, 2, 3, 4]
# Supposing that list is the final result, I would evaluate the model that holds in RANK == 0
# Is this the correct way to evaluate the performance in distributed training?
# Thanks
Nevertheless, I would appreciate feedback about if this is the correct way to solve it and if the performance would be similar regarding one-GPU training. Thanks
What I want to do is to extend the y_true to have [y_true_from_gpu0, y_true_from_gpu1]. If this is achieved, I must replicate it with y_score to have one unique AUROC metric to have the evaluation done.
You don’t need to call barrier() before all_reduce() as all_reduce() is already a synchronization point
if the performance would be similar regarding one-GPU training.
Since you are using 2 GPUs to perform evaluation and splitting the data amongst the two it should theoretically be twice as fast minus the communication overhead.