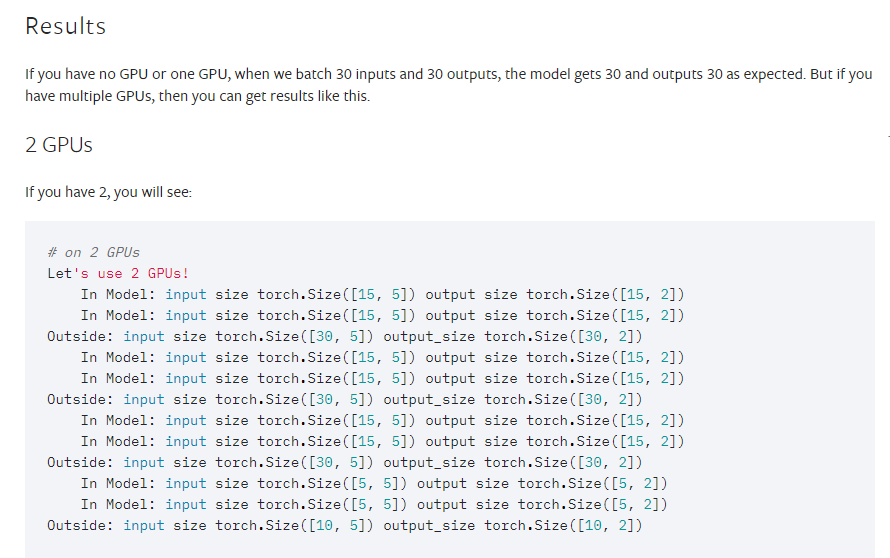
Hi, I am a newbie of Pytorch. Does anyone help me on this problem. Thanks a lot~
I just find the batch_size of output is 1/2 of the input when running my model on two GPUs. So, how to get the whole batch of output?
part of my code is as following:
device_ids = [0,1]
model = nn.DataParallel(model, device_ids=device_ids)
model = model.cuda()
print('start')
start = time.time()
for i in range(1):
inputs = torch.zeros(100, 64, 256).cuda()
outputs = model(inputs)
print(outputs.shape)
end = time.time()
print('time cost:',end-start)
where the second dim ‘64’ represents the batch_size.
Here is the results:
torch.Size([260, 50, 10000])
time cost: 3.447650671005249
Obviously the printed dimension of batch is 1/2 of the input.
I am sure the two GPUs are both used in this situation.