Hi,
I am testing out the torch.profiler for the first time with BERT fine-tuning
def trace_handler(prof):
timestamp = datetime.now().strftime("%b_%d_%H_%M_%S")
prof.export_chrome_trace(f"trace_{timestamp}.json")
prof.export_memory_timeline(f"memory_{timestamp}.html", device="cuda:0")
training_losses = []
progress_bar = tqdm(range(num_training_steps))
active_steps = 10
repeat_cycles = 1
total_profiled_steps = active_steps * repeat_cycles
current_step = 1
model.train()
with profile(
activities=[
ProfilerActivity.CPU,
ProfilerActivity.CUDA
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=active_steps, repeat=repeat_cycles),
on_trace_ready=trace_handler,
record_shapes=True,
profile_memory=True,
with_stack=True,
) as prof:
for batch in train_dataloader:
if current_step >= total_profiled_steps:
break
prof.step()
current_step += 1
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
training_losses.append(loss.item())
I only wanted to run the profiler for a few steps and stop, but I always got this error at the last step
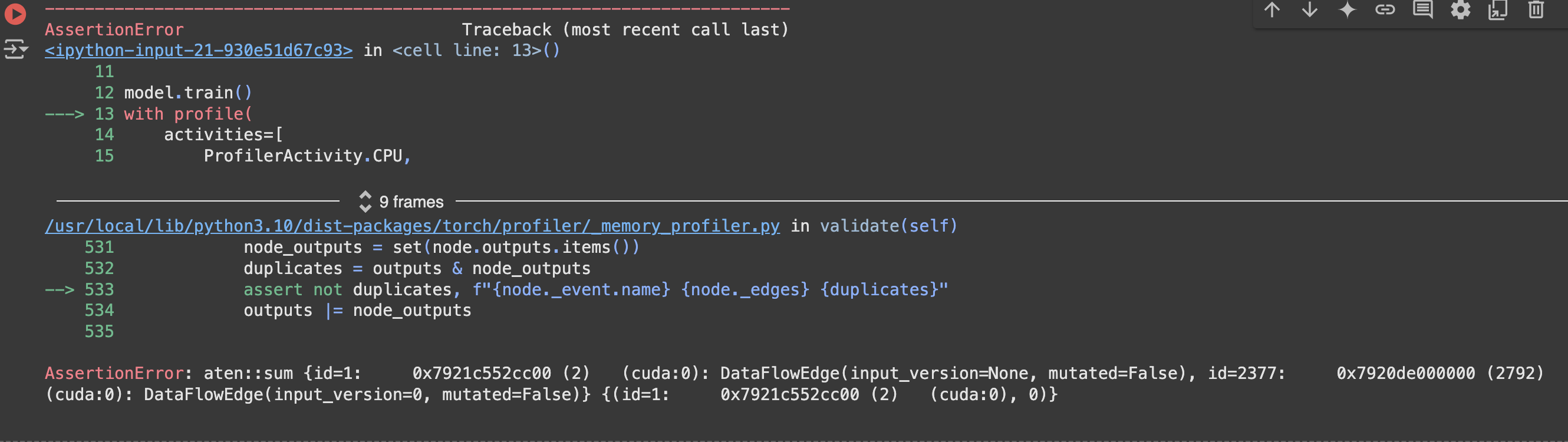
The last assertionError sometimes changes (atten:sum, atten:to, etc), but the first one would always be the ‘assert not duplicate’ line. I couldn’t really find any similar errors online, so not sure what is happening.
I am using Google Colab (GPU T4) with batch_size=4 and fine-tuning on the task of multiple choices. I have tried changing batch sizes, using torch.cuda.synchronize(), changing the active_steps numbers, but the error persisted.
Does anyone know what is happening, and where should I read more about it?