I got this error when the program running 3 batches, sometimes 33 batches, even I set the batch_size=1. I read some other topics but still don’t know how to fix it, any one can help me? thanks a lot.
my model is something like this:
def forward(self, input_id: torch.LongTensor,
token_type_id: torch.LongTensor,
attention_mask: torch.LongTensor) -> torch.FloatTensor:
print("mem free: {} Mb".format(get_gpu_memory(self.cuda_id)))
out = self.bert(input_ids=input_id,
token_type_ids=token_type_id,
attention_mask=attention_mask) # huggingface's transformers
if self.use_bert_predictions:
out = out[0]
else:
out = out[1]
out = self.encoder(out.unsqueeze(0)) # it's a LSTM
out = out[:, -1, :]
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out
my trainer is like this:
for step, trains in enumerate(train_iter):
encodes, label = trains
input_ids = torch.stack([item['input_ids']
for item in encodes[0]]).squeeze(1)
token_type_ids = torch.stack(
[item['token_type_ids'] for item in encodes[0]]).squeeze(1)
attention_masks = torch.stack(
[item['attention_mask'] for item in encodes[0]]).squeeze(1)
# outputs = []
logit = model(input_ids.cuda(config.Commom.cuda_id),
token_type_ids.cuda(config.Commom.cuda_id),
attention_masks.cuda(config.Commom.cuda_id))
loss = loss_fct(logit, label.cuda(config.Commom.cuda_id))
# outputs.append(logit.cpu().tolist())
loss /= config.Train.grad_accumulate_step
loss.backward()
if (step + 1) % config.Train.grad_accumulate_step == 0:
optimizer.step()
optimizer.zero_grad()
.....
and my error:
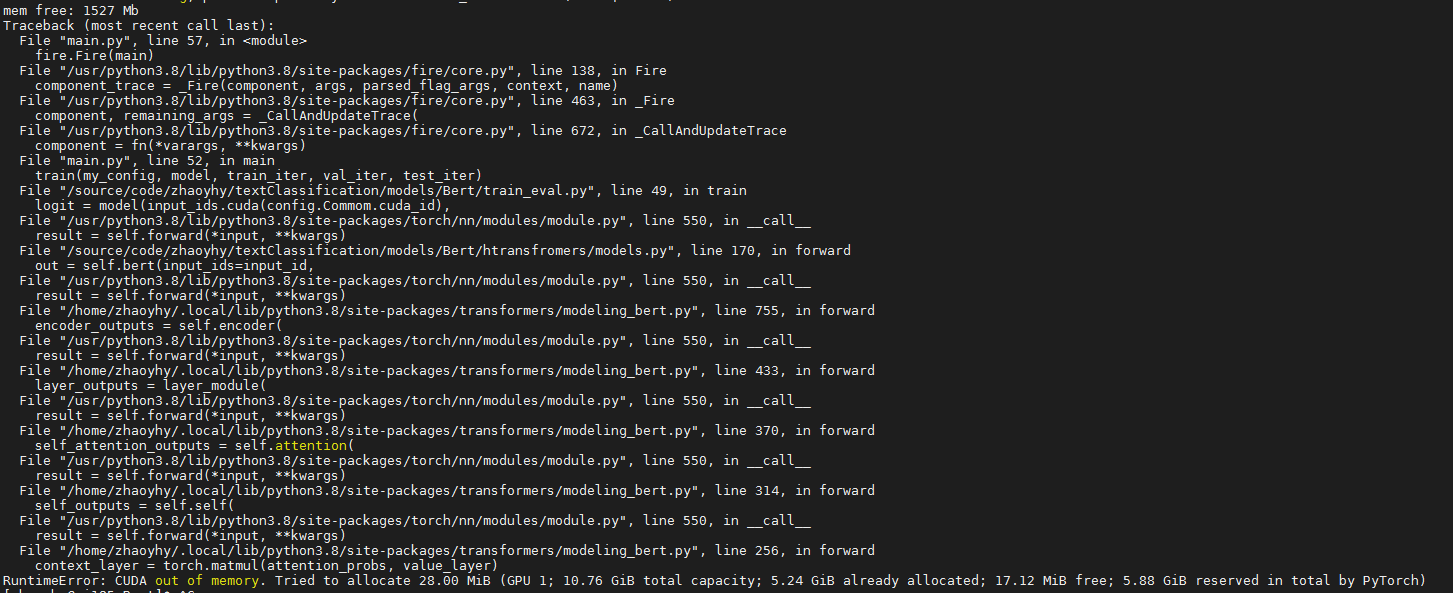
before the error, the GPU still have 1527Mb free, but can’t allocate 28.00 MiB, don’t know why