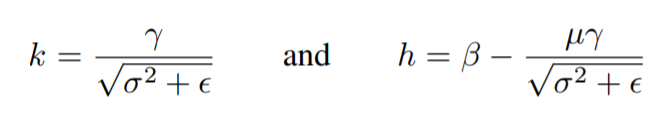This is the current batchnorm calculation:
y = \frac{x - mean}{ \sqrt{Var + \epsilon}} * gamma + beta
I want to formulate it as y=kx+b(as is shown in the picture below).
I am wandering how can I get the value of Var and mean?? Is using model.state_dict().values() function a good idea? But how can I use it while training a model? Do you have any examples to show me?
I know it’s a weird question, but if you have some suggestions, please let me know.
Do you want to use the parameters from another BatchNorm layer and just add another layer on top of it or do you want to rewrite it completely?
In the former case you could try something like this:
class MyBatchNorm(nn.Module):
def __init__(self, num_features, eps=1e-05, momentum=0.1, affine=True):
super(MyBatchNorm, self).__init__()
self.bn = nn.BatchNorm1d(num_features,
eps=eps,
momentum=momentum,
affine=affine)
def forward(self, x):
x = self.bn(x)
mu = self.bn.running_mean
var = self.bn.running_var
gamma = self.bn.weight
beta = self.bn.bias
eps = self.bn.eps
k = gamma.data / torch.sqrt(var + eps)
x.data = k * x.data + beta.data
return x
mybn = MyBatchNorm(10)
x = Variable(torch.randn(16, 10))
x_ = mybn(x)
Note that I calculated mu, var, ... separately just to show how to get them. Of course you can simplify the code and just call e.g. self.bn.weight for your calculations.
Let me know, if this meets your need or if I misunderstood your question.
when I run the code, I got this error:
RuntimeError: invalid argument 3: sizes do not match at /pytorch/torch/lib/THC/generated/…/generic/THCTensorMathPointwise.cu:351
Which Pytorch version are you using?
Could you check it with print(torch.__version__)?
Maybe your Pytorch version is a bit older and doesn’t support broadcasting yet.
I am using 0.3.0.post4. I think it is the latest Pytorch version I can get now.
Besides, I got another question quite confused me.
When I use
Blockquote
for child in model.named_children():
print(child)
layer_name = child[0]
layer_params = {}
for param in child[1].named_parameters(): #print(param)
param_name = param[0]
param_value = param[1].data.numpy()
layer_params[param_name] = param_value
save_name = layer_name + ‘.npy’
np.save(save_name,layer_params)
to save the parameters, I get gamma with 8 decimal places, and when using gamma =self.bn.weight, I can only get gamma with 4 decimal places. How’s that??
My English is not so good, so let me know if you are confused by my questions.
The Tensor and numpy array are using the same data, so it’s just a representation issue.
Try torch.set_printoptions(precision=10) and print gamma again.
Also, could you give me the line throwing the RuntimeError?
Oh, I see, that’s huge help! Thank you so much.
And the line throwing the error is:
x.data = k * x.data + beta.data
I comment out the line and it seems fine.
Blockquote
self.BinarizedConv2d2 = BinarizeConv2d(128, 128, kernel_size=3, padding=1, bias=False)
self.MaxPool2d2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.BatchNorm2d2 = BatchNorm(128)
self.Hardtanh2 = nn.Hardtanh(inplace=True)
Blockquote
This is part of my model. Could you tell me how to use the bn.running_mean directly on the model, please?
Again, you have been great help to me.Thank you so much.
And do I need to print the shape of tensors in all layers or just tensors in BatchNorm layers? Or could you please tell me the specific tensors I need to check? I am quite confused now.
Yes, you should use the output of your conv layers as the input to your batch norm.
It should also work with BatchNorm2d, if the shapes are right.
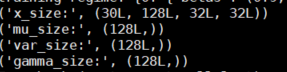
Could you print the shapes of all Tensors used in the calculation which causes the error?
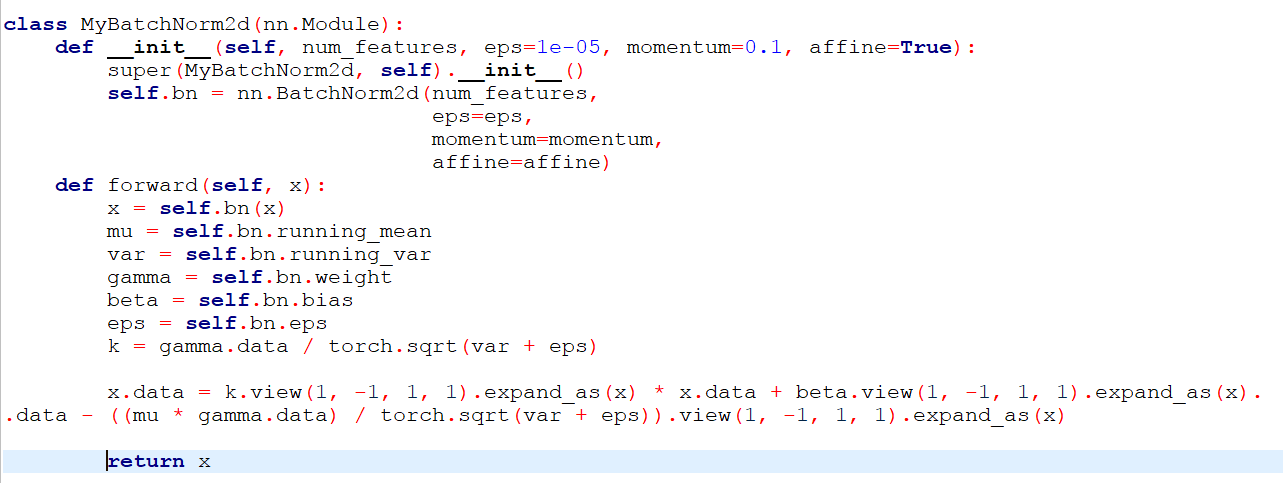
I have the same question about the batchnorm , I also need to extracte the parameters in the batchnorm. But i looked at the method you wrote MyBatchNorm, the final calculation of x.dta is incomplete, if compared with this batchnorm caluation y = \frac{x - mean}{ \sqrt{Var + \epsilon}} * gamma + beta , the lack of part of this {- mean * gamma}{\sqrt{Var + \epsilon}}. I added the program as shown in the figure below, while the program runs without error, but the cause of network loss is very serious, and so i think it is wrong to modify if, to ask you how to rewrite this part of the expression of the code, for batchnorm1d and batchnorm2d, should respectively how to write, I hope you can give answer, thank you.