I am trying to optimize memory consumption of a model and profiled it using memory_profiler. It appears to me that calling module.to(cuda_device) copies to GPU RAM, but doesn’t release memory of CPU RAM.
Is there a way to reclaim some/most of CPU RAM that was originally allocated for loading/initialization after moving my modules to GPU?
Some more info:
Line 214, uses about 2GB to initialize my model.
Line 221 or later, I no longer need this CPU RAM stuff, and I am trying to empty it (even with forced GC in line 224 didn’t help!)
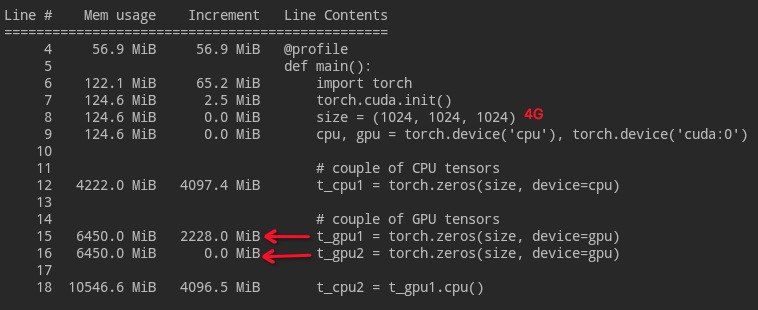
Line # Mem usage Increment Line Contents
================================================
209 88.7 MiB 88.7 MiB @profile
210 def __init__(self, exp: Experiment, model=None, lr=0.0001):
211 88.7 MiB 0.0 MiB self.exp = exp
212 88.7 MiB 0.0 MiB self.start_epoch = 0
213 88.7 MiB 0.0 MiB if model is None:
214 2159.7 MiB 2071.0 MiB model = Seq2Seq(**exp.get_model_args()).to(device)
215 2159.7 MiB 0.0 MiB last_check_pt, last_epoch = self.exp.get_last_saved_model()
216 2159.7 MiB 0.0 MiB if last_check_pt:
217 log.info(f"Resuming training from epoch:{self.start_epoch}, model={last_check_pt}")
218 self.start_epoch = last_epoch + 1
219 model.load_state_dict(torch.load(last_check_pt))
220 2159.7 MiB 0.0 MiB log.info(f"Moving model to device = {device}")
221 2159.7 MiB 0.0 MiB self.model = model.to(device=device)
222 2159.7 MiB 0.0 MiB self.model.train()
223 2159.7 MiB 0.0 MiB del model # this was on CPU, free that memory
224 2159.7 MiB 0.0 MiB gc.collect() # should the GC cleanup CPU buffers after moving to GPU ?
225 2159.7 MiB 0.0 MiB self.optimizer = optim.Adam(self.model.parameters(), lr=lr)
Update: I found what I was looking for!
Torch (in version 0.4.0) takes about 2GB CPU RAM upfront when the first cuda/GPU tensor is allocated. That was not a memory leak.
Line # Mem usage Increment Line Contents
================================================
4 29.2 MiB 29.2 MiB @profile
5 def main():
6 95.6 MiB 66.4 MiB import torch
7 95.6 MiB 0.0 MiB size = (1024, 1024, 10)
8 95.6 MiB 0.0 MiB cpu, gpu = torch.device('cpu'), torch.device('cuda:0')
9 # couple of CPU tensors
10 135.6 MiB 40.0 MiB t_cpu1 = torch.zeros(size, device=cpu)
11 175.6 MiB 40.0 MiB t_cpu2 = torch.zeros(size, device=cpu)
12 # couple of GPU tensors
13 2120.5 MiB 1944.9 MiB t_gpu1 = torch.zeros(size, device=gpu)
14 2120.5 MiB 0.0 MiB t_gpu2 = torch.zeros(size, device=gpu)
15 2120.6 MiB 0.1 MiB t_gpu3 = t_cpu1.to(gpu)
16 2080.6 MiB -40.0 MiB del t_cpu1
17 2080.6 MiB 0.0 MiB gc.collect() # does this free memory of t_cpu1 ?
18 2040.6 MiB -40.0 MiB del t_cpu2
19 2040.6 MiB 0.0 MiB gc.collect() # does this free memory of t_cpu2?
20 2040.6 MiB 0.0 MiB del t_gpu1, t_gpu2, t_gpu3
21 2040.6 MiB 0.0 MiB gc.collect() # these doesnt take any CPU RAM !!
22 2040.6 MiB 0.0 MiB del torch # remove torch module from context
23 2040.6 MiB 0.0 MiB gc.collect() # does it free everything ?
P.S.
the memory leak was somewhere else on my code, I was misled by the initial 2GB unaccounted memory.
Thanks, to anyone who attempted to answer my question!
Hello t.g,
I am facing the same problem now, i.e., “Torch (in version 0.4.0) takes about 2GB CPU RAM upfront when the first cuda/GPU tensor is allocated”.
Therefore, I am kindly asking you how you manage to solve this problem? b.t.w, what do you mean by “misled by the initial 2GB unaccounted memory”?