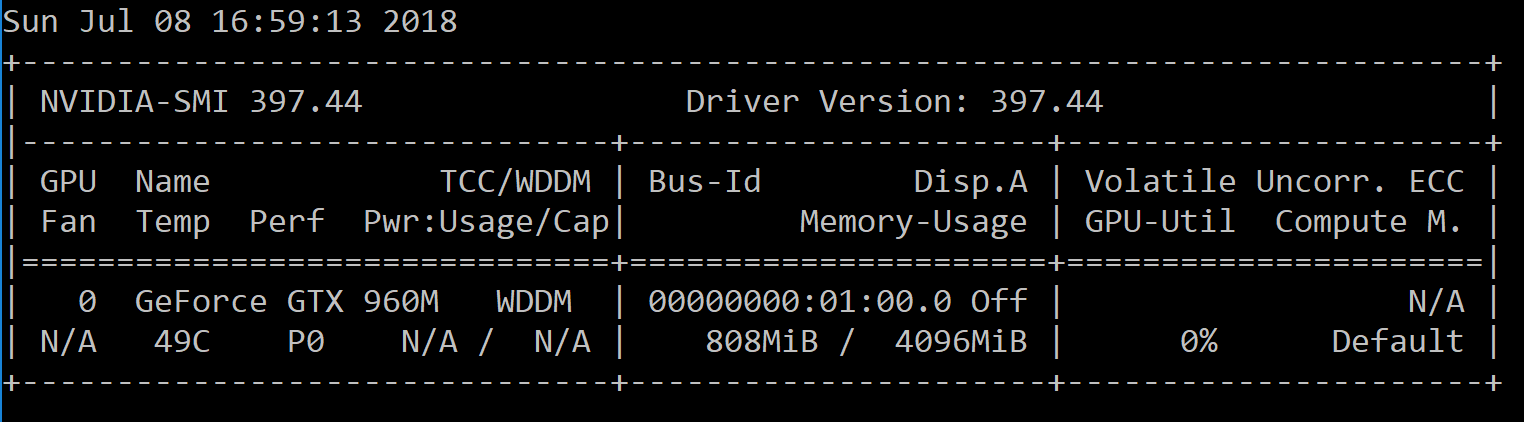
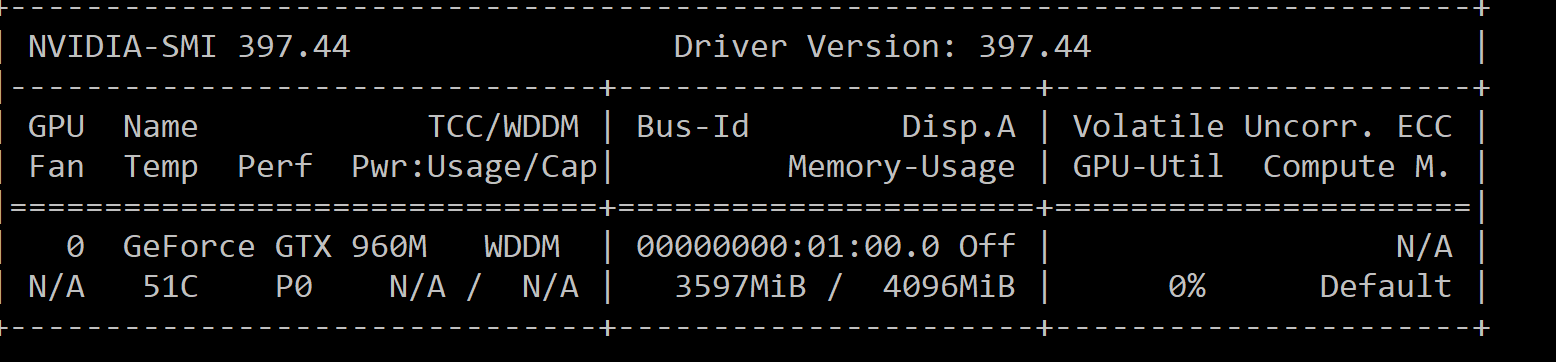
I am using a VGG16 pretrained network, and the GPU memory usage (seen via nvidia-smi) increases every mini-batch (even when I delete all variables, or use torch.cuda.empty_cache() in the end of every iteration). It seems like some variables are stored in the GPU memory and cause the “out of memory” error. I couldn’t solve the problem by using any of the other related posts in this forum.
Will you please help me understand how I can free all possible GPU memory after each mini-batch? If possible, will you please explain to me why some variables are stored in the GPU memory and are deleted from the memory when using the “del” command?
Attached below is a minimal example that reproduces the “out of memory” error I get
Thanks a lot
transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = dset.ImageFolder(root="......", transform=transform )
model = models.vgg16(pretrained=True)
num_features = model.classifier[6].in_features
features = list(model.classifier.children())[:-1] # Remove last layer
features.extend([nn.Linear(num_features, 2)]) # Add our layer with 2 outputs
model.classifier = nn.Sequential(*features) # Replace the model classifier
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0005)
criterion = nn.CrossEntropyLoss()
model = model.cuda()
criterion = criterion.cuda()
train_loader = DataLoader(trainset, batch_size=4, shuffle=True, drop_last=True)
train_iterator = iter(train_loader)
for i in range(num_of_mini_Batches):
img, label= next(train_iterator)
img = Variable(img.cuda(), requires_grad=True)
label= Variable(label.cuda() )
optimizer.zero_grad()
outputs = model(img)
loss = criterion(outputs, label)
loss.backward()
# del loss, model, outputs, optimizer, img, label, train_loader, train_iterator
# torch.cuda.empty_cache()
optimizer.step()