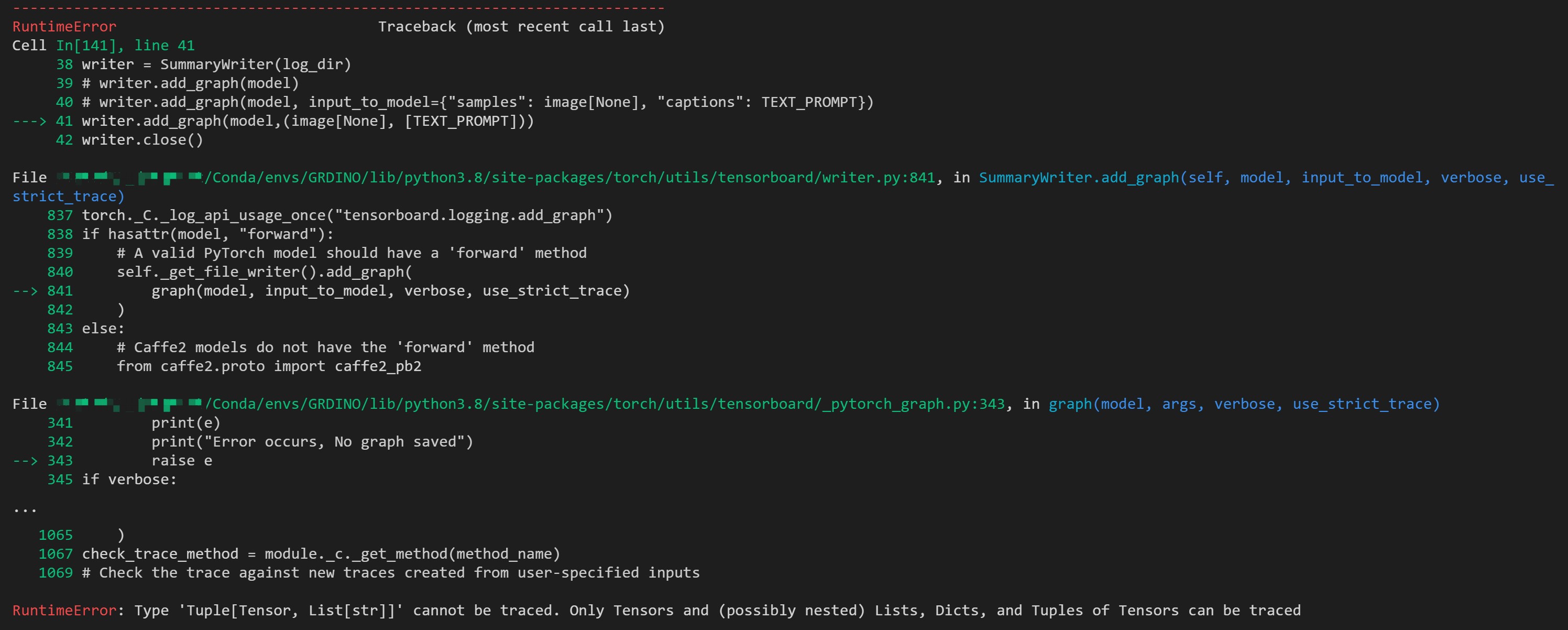
These days, a popular open-set object detector called Grounding DINO was proposed. By marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. I try to visualize the model architecture with tensorboard. But when I pass the image and ‘TEXT_PROMPT’ after the preprocess_caption function, the error comes "RuntimeError: Type ‘Tuple[Tensor, List[str]]’ cannot be traced. The code block is as follows:
import os
def preprocess_caption(caption: str) -> str:
result = caption.lower().strip()
if result.endswith("."):
return result
return result + "."
CONFIG_PATH = os.path.join(HOME, "groundingdino/config/GroundingDINO_SwinT_OGC.py")
print(CONFIG_PATH, "; exist:", os.path.isfile(CONFIG_PATH))
WEIGHTS_NAME = "groundingdino_swint_ogc.pth"
WEIGHTS_PATH = os.path.join(HOME, "weights", WEIGHTS_NAME)
print(WEIGHTS_PATH, "; exist:", os.path.isfile(WEIGHTS_PATH))
IMAGE_NAME = "dog-3.jpeg"
IMAGE_PATH = os.path.join(HOME, "data", IMAGE_NAME)
TEXT_PROMPT = "chair"
TEXT_PROMPT = preprocess_caption(TEXT_PROMPT)
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
model = load_model(CONFIG_PATH, WEIGHTS_PATH)
image_source, image = load_image(IMAGE_PATH)
with torch.no_grad():
outputs = model(image[None], captions=[TEXT_PROMPT])
log_dir = "./logs"
writer = SummaryWriter(log_dir)
writer.add_graph(model, input_to_model={"samples": image[None], "captions": TEXT_PROMPT})
writer.add_graph(model,(image[None], [TEXT_PROMPT]))
writer.close()
the error comes “Only Tensors and (possibly nested) Lists, Dicts, and Tuples of Tensors can be traced”.
Because the text and image backbone deal with corresponding data at the beginning of Grounding DINO, How can I pass the input to the add_graph function? I also tried the netron.app with the .pth file, but it didn’t have the link between the layers.
Could you please give some advice to solve the visualization problem? Thanks!