Hello PyTorchers.
I used the word PyTorcher meaning the person uses Pytorch.
I am not sure this expression is appropriate, so comment to me about this, please XD
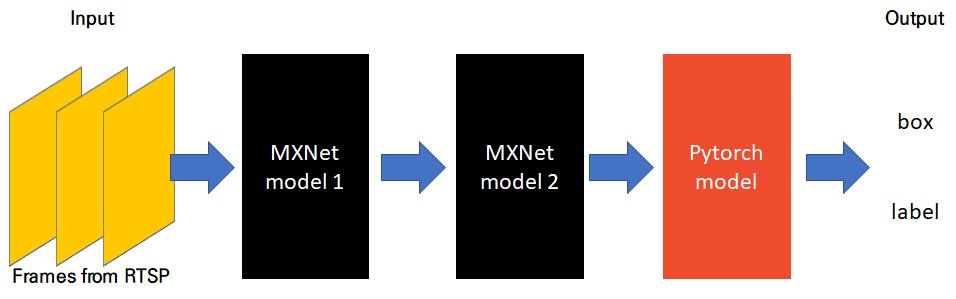
For my task (face detection), I am using two deep learning framework, Pytorch and MXNet.
Please look at the diagram below to help your understanding.
When the code was first implemented, GPU was used for the process above.
But the inference time was not that fast.
To compare inference time, I later have created other codes that use CPU only(installed No CUDA libraries).
I found that there was no difference between GPU processing and CPU processing in terms of inference time. (I measure FPS but there was no dramatic difference.)
Could you give me ideas to use GPU efficiently for fast inference?
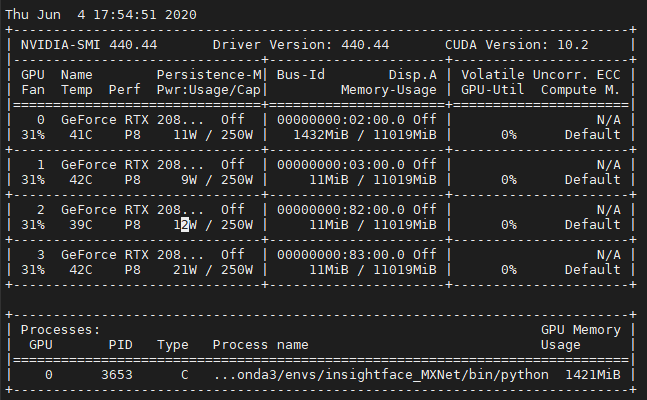
Is this normal that the Volatile GPU-util is almost 0% when PyTorch model is on inference mode?
I capture the RTSP frame using VideoStream class from imutils package which use cv2 and thread package. Do you have any idea for fast realtime ( < 2 sec delay) visualization?
I will definitely respond to all of your comments.
How did you implement the communication between MXNet and PyTorch?
The GPU utilization might be low, if your workload is small or if your application has a bottleneck in another part of the code.
How large is your input and how fast is the data loading (including MXNet processing) compared to the forward pass of your PyTorch model?
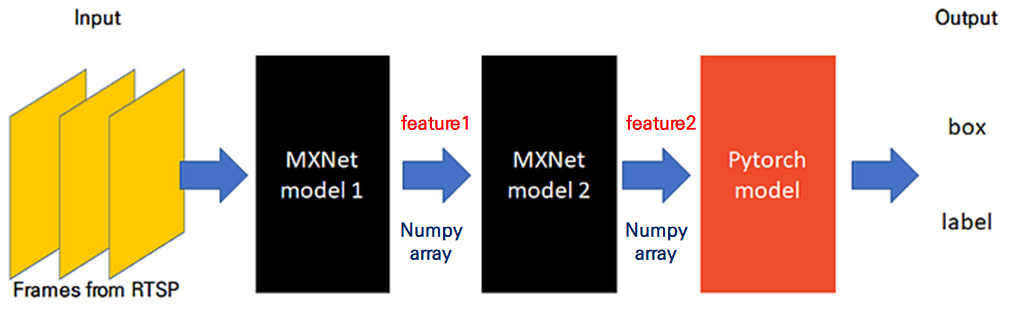
In that case you are adding synchronizations, as numpy uses CPU arrays. Your workflow would therefore probably be:
load data on CPU -> transfer to GPU and use MXNet model -> transfer back to CPU -> transform to PyTorch tensor and transfer back to GPU -> use forward pass of PyTorch model -> prediction
which most likely won’t benefit a lot from the GPU. You could try to use both models on the CPU only and compare the processing time. Since you are synchronizing and also transferring the data between the host and device multiple times, the GPU utilization could be low.
Especially for small inputs, the workload on the GPU is small and you might see the overhead of the kernel launch times as well as the data transfer.
Note that CUDA operations in PyTorch are asynchronous, so you would need to synchronize the code manually to profile the desired operation before starting and stopping the timer via torch.cuda.synchronize().