.grad() method returns gradient values for each weight in the network. However, how can I get gradient values for each node in the network? Or is it safe to simply add gradients for each weight that corresponds to a specific node?
I’m not sure I understand the question properly.
Could you explain your definition of weight vs. node, please? ![]()
Yes, of course! Sorry for not being clear.
Let’s say I have a super simple network that has an in_feature dimension of 3 and an out_feature dimension of 5 and in Pytorch, this calculation would be done with a matrix multiplication (nn.Linear(3, 5))
model = nn.Sequential(
nn.Linear(3, 5)
)
loss.backward()
Then, calling .grad() on weights of the model will return a tensor sized 5x3 and each gradient value is matched to each weight in the model. Here, I mean weights by connecting lines in the figure below.
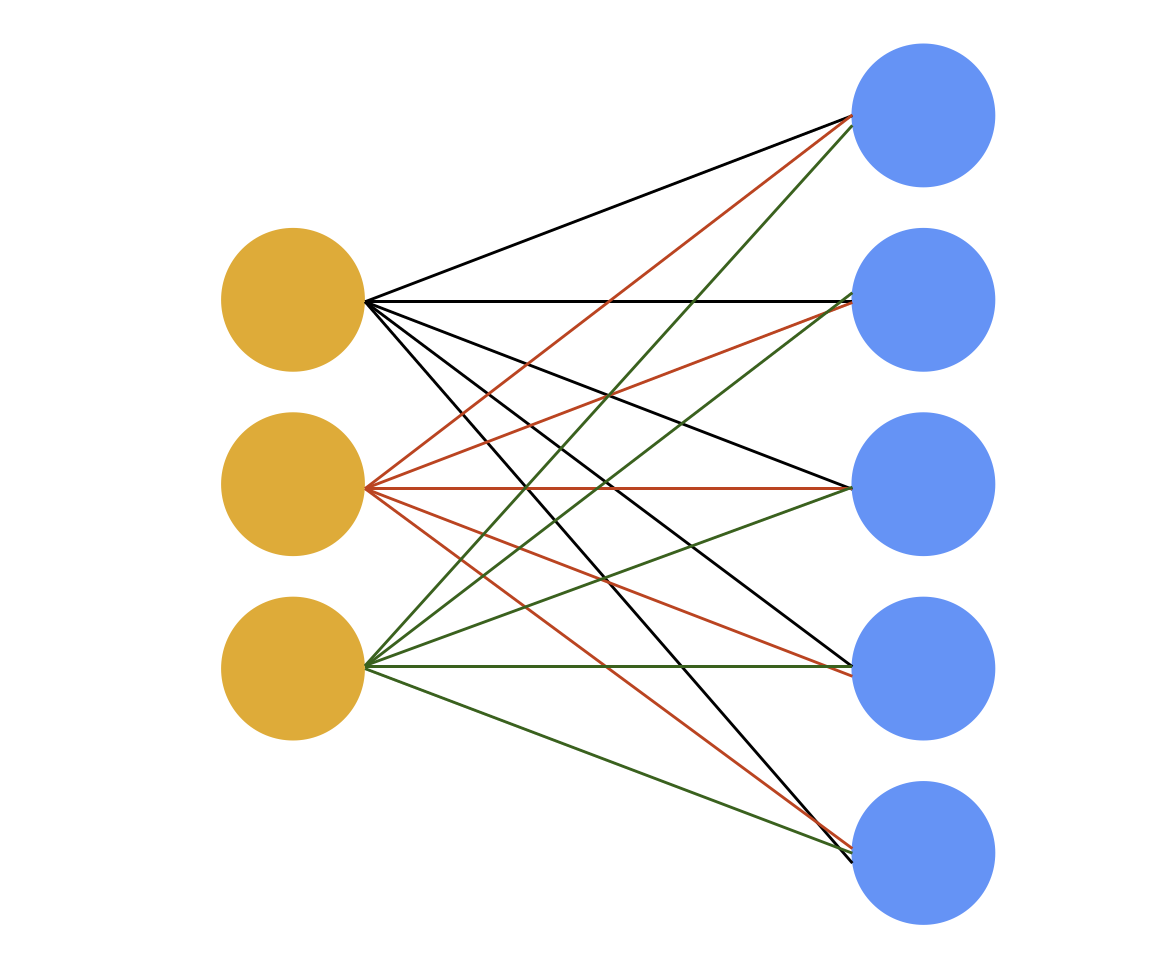
However, I was wondering how to get gradients for each of the 3 in_feature dimensions, which are the yellow dots (nodes). Would summing the 5x3 sized gradient matrix into the dimension of 3 be a safe way to get them?
I was wondering if you might be able to get this via using a backward hook? Because it seems like you’re looking for the grad_input of a layer? Does that work @ptrblck ?
Just to clarify that my question wasn’t specifically toward on gradients w.r.t the input but it was for those neurons in the network in general. So if the network was deeper than the example above, I’d like to get gradients of each and every neuron of the network! Any help would be appreciated ![]()
yes, but surely the neurons are just inputs of a given layer? So, if all your layers are just nn.Module objects you should be able to get the gradient with respect to each neuron via the backward hook?
Note: the backward hook returns the gradients for each input in your batch too, so you may need to take the mean over the batch dim to get the shape you want.
I agree with @AlphaBetaGamma96’s suggestions and think backward hooks should work to get the gradient for the input activations.
Make sure to use register_full_backward_hook and not register_backward_hook as register_backward_hook is deprecated and gives unexpected behaviour!
I was able to get gradient information w.r.t every layer in my model with register_full_backward_hook . Thank you ![]()
I have an additional question on the behavior of register_full_backward_hook.
Below is the printed output of my code with register_full_backward_hook and I expect input grad shape and output grad shape for nn.Linear(512, 512) would be torch.Size([12, 512]) and torch.Size([12, 512]) each (12 is the size of the mini-batch). However, it’s giving me another dimension of 30.
hook triggered on Linear(in_features=512, out_features=512, bias=False)
input grad shape: torch.Size([12, 30, 512])
output grad shape: torch.Size([12, 30, 512])
Do you have any idea where that 30 comes from?
Are you passing an input of [12, 30, 512] to this layer as seen here?
def hook(module, grad_input, grad_output):
print(grad_input[0].shape)
print(grad_output[0].shape)
lin = nn.Linear(512, 512, bias=False)
lin.register_full_backward_hook(hook)
x = torch.randn(12, 30, 512, requires_grad=True)
out = lin(x)
out.mean().backward()
Output:
torch.Size([12, 30, 512])
torch.Size([12, 30, 512])
Oh yes! Just checked the input dimension size and turns out the layer was getting an input of torch.Size([12, 30, 512]). Thank you so much!