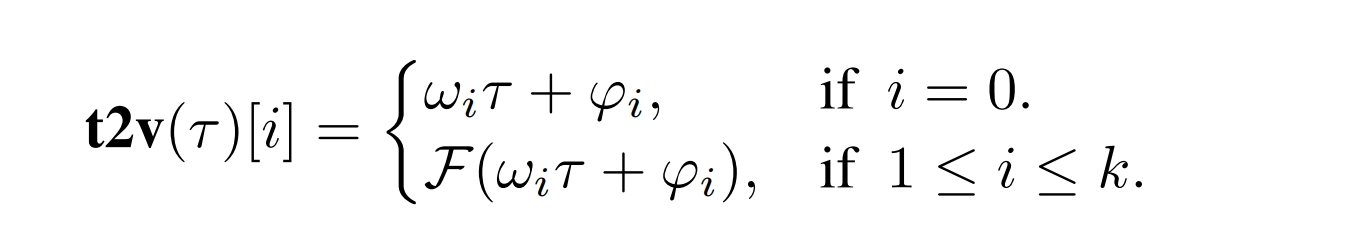I would like to implement a custom layer but I can’t get the shapes correct because of the batch dimension in the forward path. I however tried to make it exactly the way nn.Linear is implemented. What am I missing here?
import torch as t
import torch.nn as nn
from torch.nn import init
class Time2Vec(nn.Module):
"""
source: https://towardsdatascience.com/time2vec-for-time-series-features-encoding-a03a4f3f937e
and: https://arxiv.org/pdf/1907.05321.pdf
"""
def __init__(self, input_dim, output_dim):
super().__init__()
self.output_dim = output_dim
self.W = nn.Parameter(t.Tensor(output_dim, output_dim))
self.B = nn.Parameter(t.Tensor(input_dim, output_dim))
self.w = nn.Parameter(t.Tensor(1, 1))
self.b = nn.Parameter(t.Tensor(input_dim, 1))
self.reset_parameters()
def reset_parameters(self):
init.uniform_(self.W, 0, 1)
init.uniform_(self.B, 0, 1)
init.uniform_(self.w, 0, 1)
init.uniform_(self.b, 0, 1)
def forward(self, x):
original = self.w * x + self.b
x = t.repeat_interleave(x, self.output_dim, dim=-1)
sin_trans = t.sin(t.dot(x, self.W) + self.B)
return t.cat([sin_trans, original], -1)
And create a module:
class MyModule(nn.Module):
def __init__(self, input, output):
super().__init__()
self.net = Time2Vec(input, output)
def forward(self, x):
return self.net(x)
t2v = MyModule(3, 3)
print(t2v(t.from_numpy(np.array([[[0.1], [0.2], [0.3]], [[0.1], [0.2], [0.3]]])).float()))
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 0