Hi,
I am trying to implement a variation of BatchNorm and want to use the current code first.
My problem is how to find the batch_mean and batch_std inside the current BatchNorm module.
In the old implementation torch/legacy/nn/BatchNormalization.py:
There are save_mean and save_std parameters are generated after forward pass. However, these two parameters are removed in the current version. Is there any way I can achieve these two parameters in the current version?
You could get the running mean and var (exponentially weighted average from last batches) with bn.running_mean and bn.running_var, if that is what you need.
Hi Thanks!
But actually I want the batch_mean and batch_var which were used during the training.
I am implementing the batch renomalization paper https://arxiv.org/abs/1702.03275. Both batch_mean, and running_mean are used during training. Is there any way to access both variables? I am pretty sure they are stored in some way to accelerate the backward propagation.
Inside the batch_norm function, torch._C._functions.BatchNorm calculates the batch_mean and batch_var first, and then use them to normalize the batch and update the running_mean and running_var. These two parameters are stored in inside the function. I am wondering is there any easy way I can access this two parameters?
No, there is no easy to do it. Due to the performance, the batch mean/std calculation is inside the cuDNN and used to update the running mean/std directly.
The simple way to do it is running a batch norm module but set it in the evaluation mode. Then you can get the batch mean/std easily in the training.
What I do is to use a hook to inspect the input and output to the batchnorm layer, and I compute the mean and variance of the input to the layer (which should be roughly the same to the one computed by torch._C._functions.BatchNorm).
Example:
# 1. define model
model = ...
# 2. register the hook
model.bn_layer.register_forward_hook(printbn)
# 3. the hook function will be called here
model.forward(...)
and the hook can be defined as:
def printbn(self, input, output):
print('Inside ' + self.__class__.__name__ + ' forward')
mean = input[0].mean(dim=0)
var = input[0].var(dim=0)
print(mean)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = torch.flatten(x, 1)
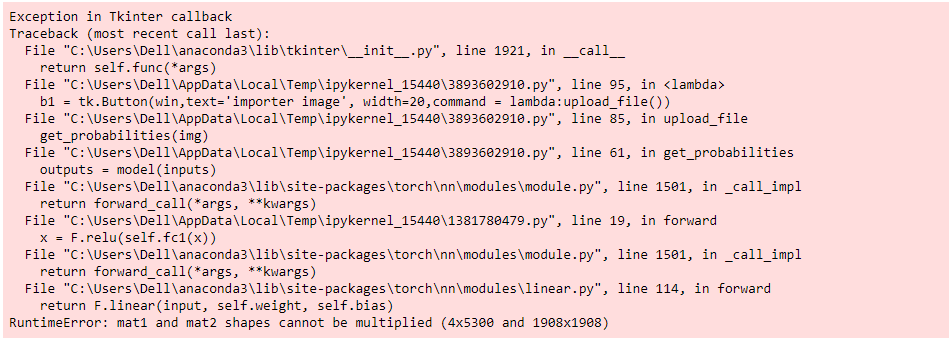
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”) # PyTorch v0.4.0
model = Net().to(device)
summary(model, (3, 144, 144))
The in_features of self.fc1 doesn’t match the feature size of x, so you would need to fix it.
I also don’t know how your post is related to this topic.