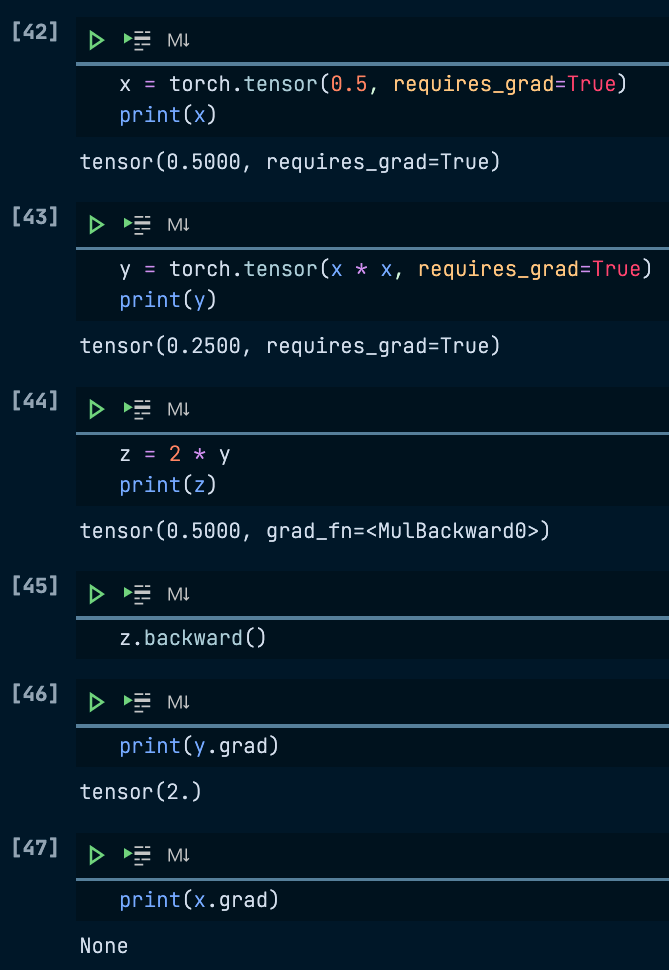
Assuming the following forward pass: x → y → z, in which
x is a scalar
y = x * x
z = 2 * y
I want to track the following derivatives/gradients, including the gradient for the intermediate function y:
dz/dy, gradient of z with respect to y, which should be “2”
dy/dx, gradient of y with respect to x, which should be “2x”
dz/dx, gradient of z with respect to x, which should be “4x”
So, I initiated both x and y with the requires_grad=True argument. However, I can only get y.grad, which is “2”, and x.grad returned “None”, as shown below.
May I ask:
Why I’m unable to get x.grad (dz/dx) in this case?
How to get the gradients for both the input and intermediate variables via .backward()?
Your code should raise a warning and explain the reason and workaround for it:
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
print(y.grad)
After adding y.retain_grad() you’ll get the gradient value for y.