I’m working on a project where I need to map FX node names to their corresponding ONNX node names, particularly after exporting an FX GraphModule to ONNX. The naive approach I’ve been using involves iterating through node types and maintaining a counter to track node names, as shown in the pseudo-code below:
def get_onnx_to_fx_node_name_mapping(graph_module):
counters = defaultdict(int)
def guess_onnx_node_name(fx_node):
onnx_node_name = FX_TO_ONNX_NODE_TYPE_MAPPING.get(str(fx_node.target))
count = counters[onnx_node_name]
counters[onnx_node_name] += 1
return onnx_node_name if count == 0 else f'{onnx_node_name}_{count}'
return {
guess_onnx_node_name(fx_node): fx_node.name
for fx_node in graph_module.graph.nodes
}
However, certain FX nodes like GELU are decomposed into multiple nodes during ONNX conversion. This decomposition results in inaccurate mappings, particularly for nodes like Add that cannot be correctly mapped with this straightforward solution.
Additionally, other FX nodes like aten.linear may convert to either Gemm or Matmul in ONNX, depending on conditions that are currently unclear to me.
Here’s an example using a simple model that illustrates the issue:
import torch
from torch import nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 3, 3, 1)
self.conv2 = nn.Conv2d(3, 3, 3, 1)
self.gelu = nn.GELU()
def forward(self, x):
y1 = self.gelu(self.conv1(x))
y2 = self.gelu(self.conv2(x))
return y1 + y2
model = Net().eval()
example_inputs = (torch.randn(1, 3, 32, 32),)
gm = torch._export.capture_pre_autograd_graph(model, example_inputs)
gm.graph.print_tabular()
# Ignore train to enable export onnx
def train(self, *args, **kwargs):
return self
gm.train = train.__get__(gm)
torch.onnx.export(gm, example_inputs, 'conv_gelu.onnx', opset_version=17)
The FX tabular output for this model is as follows:
opcode name target args kwargs
------------- ---------------- ------------------- ------------------------------------------ --------
placeholder arg0 arg0 () {}
get_attr _param_constant0 _param_constant0 () {}
get_attr _param_constant1 _param_constant1 () {}
call_function conv2d_default aten.conv2d.default (arg0, _param_constant0, _param_constant1) {}
call_function gelu_default aten.gelu.default (conv2d_default,) {}
get_attr _param_constant2 _param_constant2 () {}
get_attr _param_constant3 _param_constant3 () {}
call_function conv2d_default_1 aten.conv2d.default (arg0, _param_constant2, _param_constant3) {}
call_function gelu_default_1 aten.gelu.default (conv2d_default_1,) {}
call_function add_tensor aten.add.Tensor (gelu_default, gelu_default_1) {}
output output output ([add_tensor],)
And the corresponding ONNX graph shows that the last Add node is named Add_2 instead of Add, due to the decomposition of GELU into additional nodes. So I get a wrong mapping from add_tensor to Add.
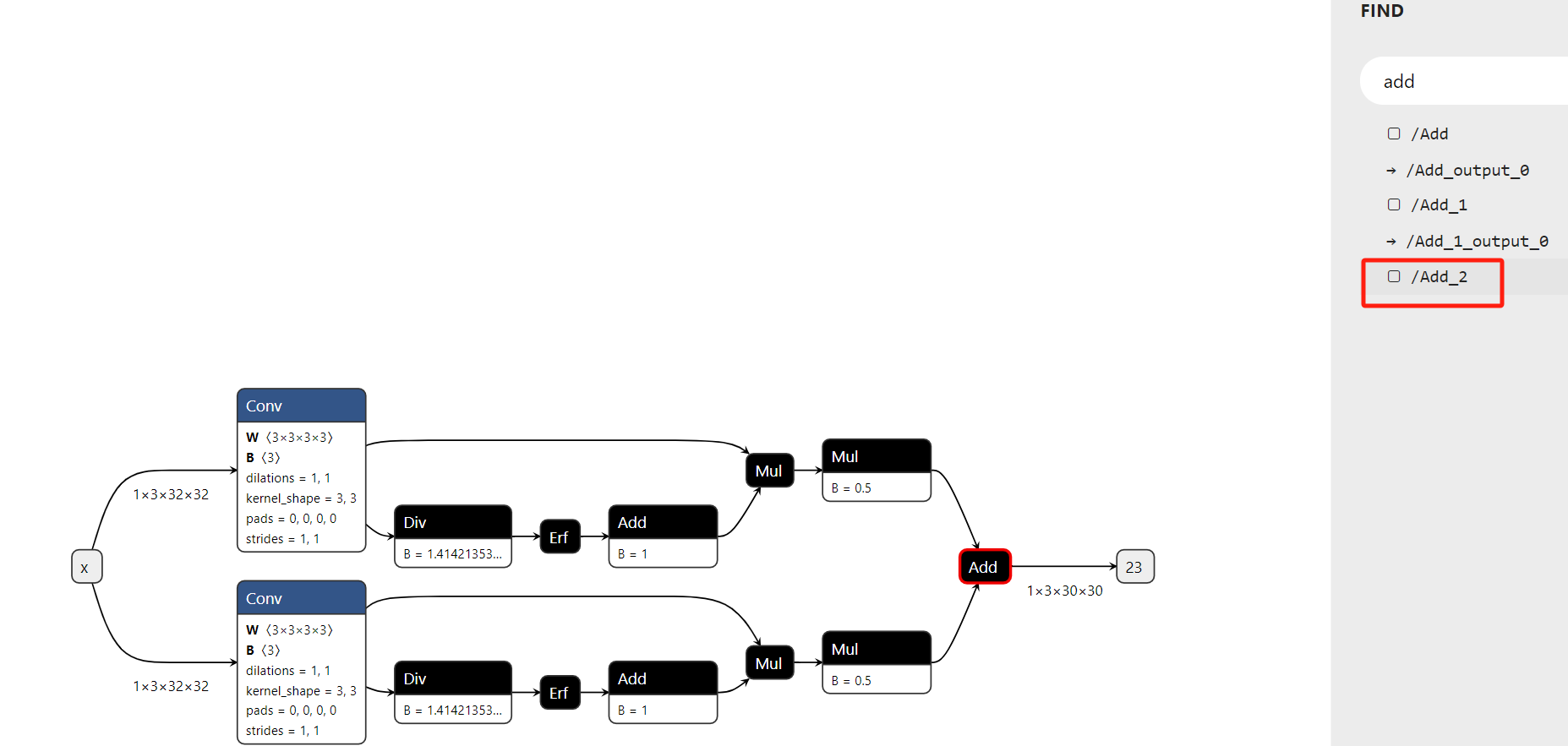
I am seeking advice on how to enhance the robustness of this mapping process. Is there an established method for accurately mapping FX node names to ONNX node names, especially in cases where nodes are decomposed or have conditional mappings?