Hello everyone.
I’m dealing with a binary classification problem that has imbalanced data. basically the dataset is about identifying live vs impersonate . basically its a real vs fake classification.
There are already many questions regarding this in the forum, but I’m kind of lost at the moment and I’m not sure if I’m doing it wrong or the issue stems from somewehre/something else.
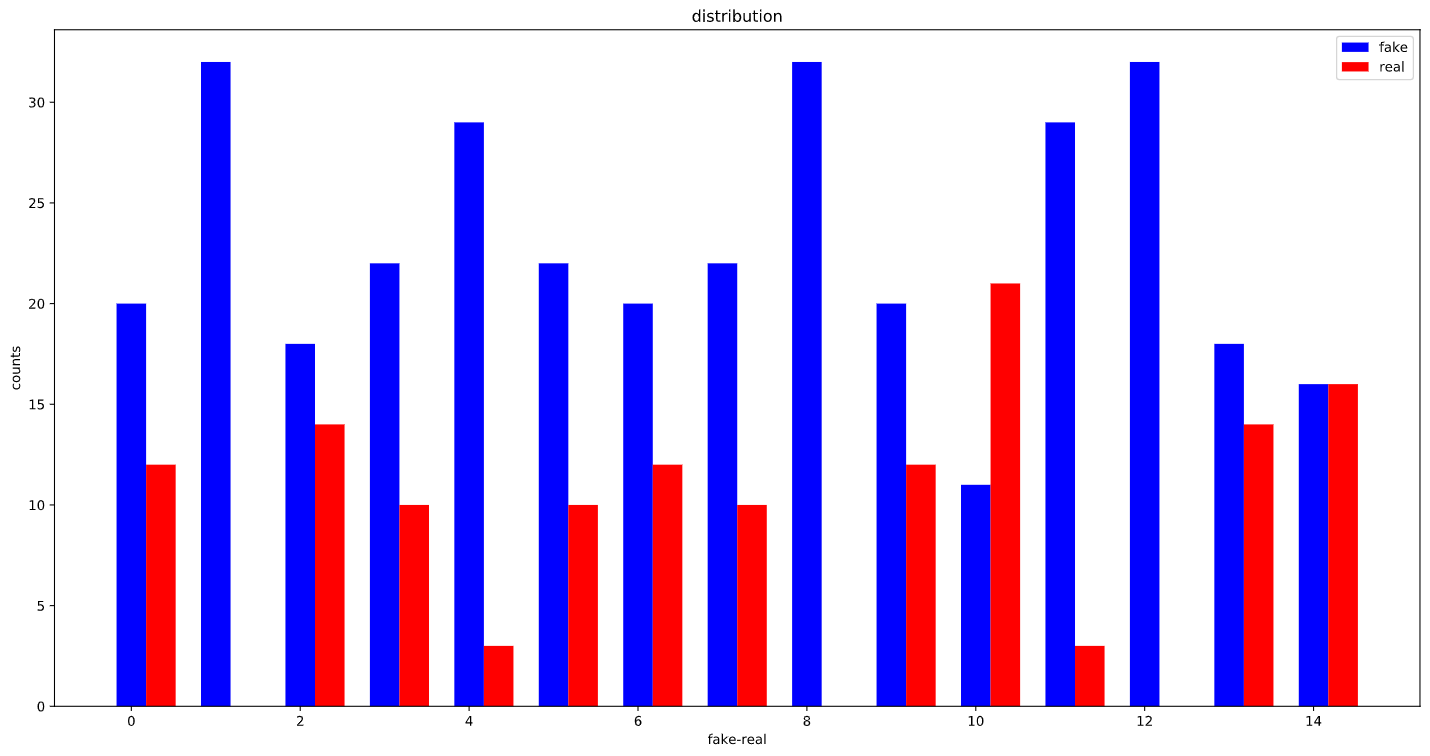
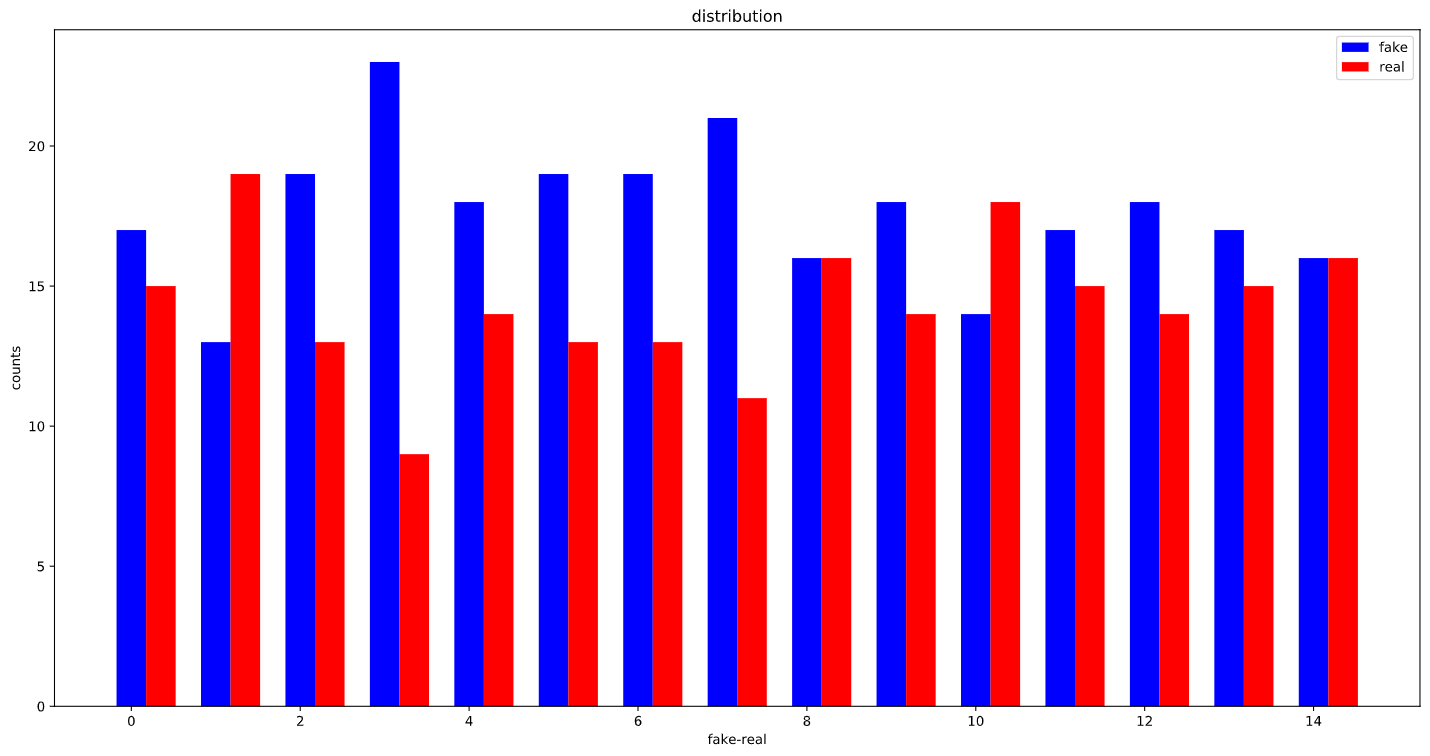
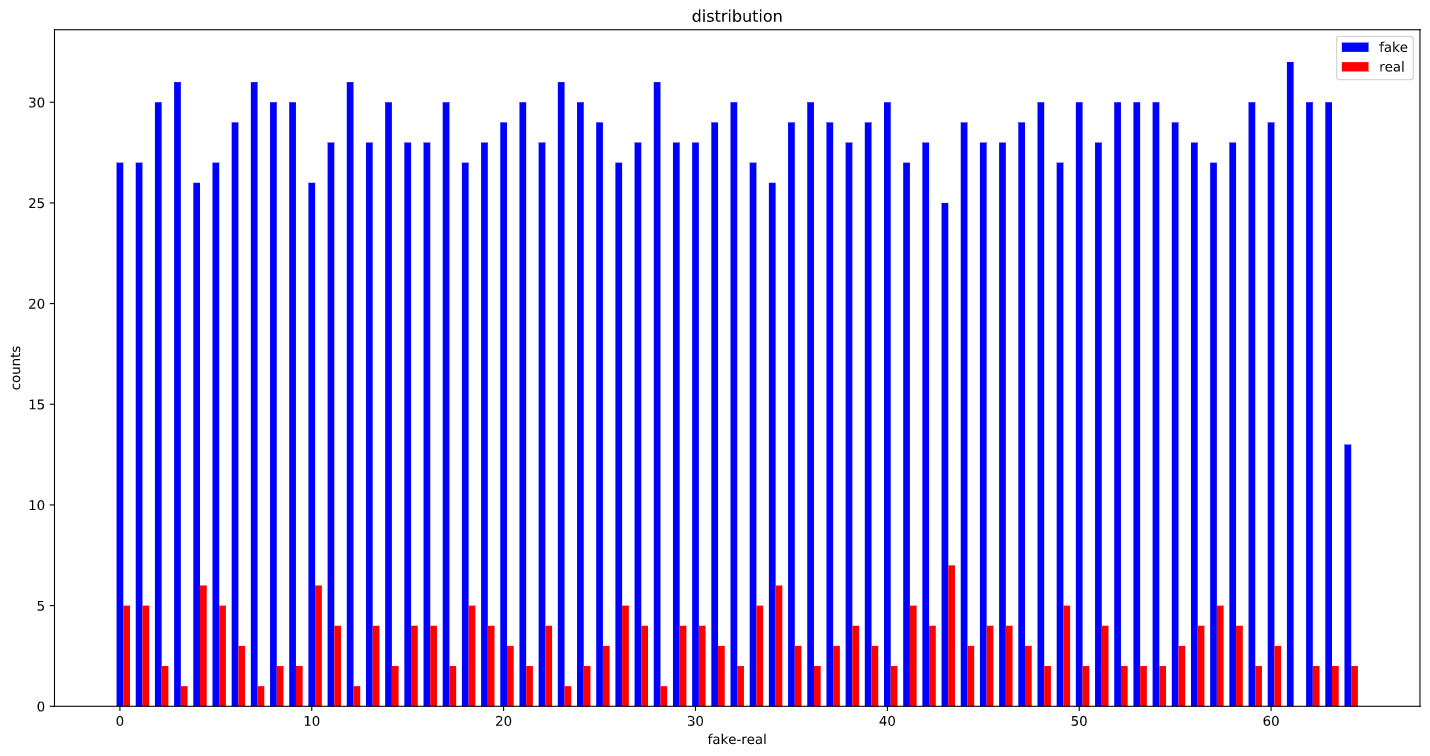
Here is how the training set distribution looks like :

There are 505 samples for real and 1558 samples for fake class. totaling to 2063 samples in the whole dataset.
Now there are two ways to tackle this issue as far as I know, oversampling and weighted loss.
I went for the oversampling solution and tried to use WeightedRandomSampler .
This is how I implemented the sampler:
dt_train = FASDataset(root=os.path.join(cdir, 'CASIA_faceAntisp', 'train_release_imgs'), transformations=trans_train)
num_classes = 2
class_sample_counts = [dt_train.real_sample_count, dt_train.fake_sample_count]
# compute weight for all the samples in the dataset
# samples_weights contain the probability for each example in dataset to be sampled
# shouldnt we do highestclass/class_c for all classes? that is do :
# [dt_train.fake_sample_count/dt_train.real_sample_count, dt_train.fake_sample_count/dt_train.fake_sample_count]
class_weights = 1./torch.Tensor(class_sample_counts)
# get list of all labels
train_targets = dt_train.get_labels(True)
# then get the weight for each target!
train_samples_weight = [class_weights[class_id] for class_id in train_targets]
train_sampler = WeightedRandomSampler(train_samples_weight, len(train_samples_weight), replacement=True)
dl_train = torch.utils.data.DataLoader(dt_train, sampler=train_sampler, batch_size=32, pin_memory=True, shuffle=(train_sampler==None))
and the dataset itself looks like this :
class FASDataset(torch.utils.data.Dataset):
def __init__(self, root, transformations=tf.ToTensor()):
"""
"""
super().__init__()
# read the files for training and testsets
self.root= root
self.transforms = transformations
self.img_list = []
self.real_sample_count = 0
self.fake_sample_count = 0
self.num_classes = 2
self.classes = {0:'fake', 1:'live'}
for dir_path, dirnames, filenames in os.walk(root):
for filename in filenames:
img_path = os.path.join(dir_path, filename)
label = self._get_label(img_path)
self.img_list.append((img_path, label))
self.real_sample_count += int(label)
self.fake_sample_count = len(self.img_list) - self.real_sample_count
def plot_data_distribution(self):
plt.figure(figsize=(15,8))
sns.barplot(data=pd.DataFrame.from_dict([self.class_distributions]).melt(),
x="variable", y="value", hue="variable").\
set_title('Fake/Real Class Distribution')
plt.show()
def get_labels(self, return_as_ints=False):
integer = lambda x : int(x) if return_as_ints else x
return [integer(label) for _,label in self.img_list]
def _get_label(self, image_full_path):
filename = os.path.split(image_full_path)[-1]
# only the files starting with 1_, 2_ and HR_1 are real/positive samples, the rest are negative samples
# for example, 1_img_0.jpg, 1_img_1.jpg, ... 2_img_0.jpg, ... HR_1_img.jpg are positive examples
# and 3_img_0.jpg ..., HR_2_img_0.jpg, etc are negative examples
return float(re.match(r"((^1_)|(^2_)|(^HR_1))", filename) != None)
def __getitem__(self, index):
(image_file, label) = self.img_list[index]
img = Image.open(image_file)
if self.transforms:
img = self.transforms(img)
return img, label
def __len__(self):
return len(self.img_list)
and my forward looks like this :
class MyNet(nn.Module) :
def __init__(self)
super().__init__()
self.features = ...
self.classifier = nn.Linear(32, 1)
def forward(self, input_batch):
output = self.features(input_batch)
output = F.max_pool2d(output, kernel_size=output.size()[2:])
output = output.view(-1, 32)
output = self.classifier(output)
# we use BCEwithlogits for more numerically stable training, so we dont use sigmoid here
# output = torch.sigmoid(output)
return output
def predict(self, input_batch):
out_raw = self.forward(input_batch)
out_sig = torch.sigmoid(out_raw)
preds = torch.round(out_sig)
return preds
and the training :
def train_val(model, dataloader, optimizer, is_training, device, interval):
batch_cnt = len(dataloader)
status = 'Training' if is_training else 'validation'
# we use BCEWithLogits which uses sigmoid internally
criterion = torch.nn.BCEWithLogitsLoss()
total_loss = 0.0
accuracy = 0.0
with torch.set_grad_enabled(is_training):
model.train() if is_training else model.eval()
for i, (imgs, labels) in enumerate(dataloader):
imgs = imgs.to(device)
preds = model(imgs)
loss = criterion(preds.cpu().view(*labels.shape), labels.cpu())
total_loss += loss.item()
if is_training:
optimizer.zero_grad()
loss.backward()
optimizer.step()
accuracy += binary_acc(preds.cpu(), labels.cpu())
accuracy = accuracy/batch_cnt
total_loss = total_loss/batch_cnt
print(f'[{status}] acc: {accuracy:.2f} loss: {total_loss:6f}')
return accuracy, total_loss
So this is the basic building block that I’m using and as you can see they are pretty normal.
Now I have some questions concerning all of this :
First of all, am I doing it correctly ? is the way I’m creating the WeightedRandomSampler alright?
For example :
1.Shouldnt we for example divide all the sample counts from the highest class sample count? I mean doing
class_weights = [dt_train.fake_sample_count/dt_train.real_sample_count, dt_train.fake_sample_count/dt_train.fake_sample_count]
instead of:
class_weights = 1./torch.Tensor(class_sample_counts)
and
2. Shouldn’t we use the batch_size for the WeightedRandomSampler instead of the the actual len(train_samples_weight) ?
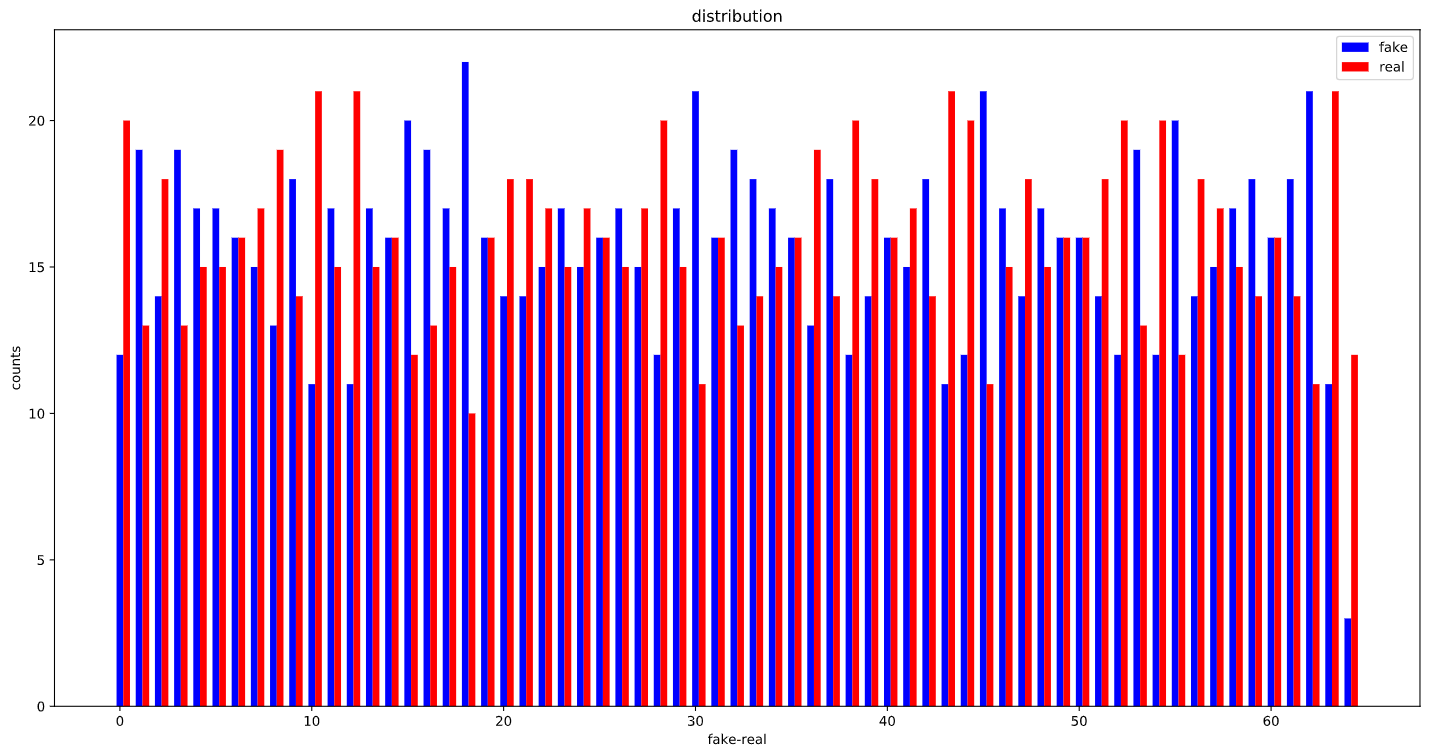
Becasue if I use the later, the network achives a very high acc (100% train and 96% validation, and as you can guess, it just predicts the fake class!) if I use batch_size, the accuracies drop but ultimately, it will reaach 99% train and 93% validation whcih this time, it predicts all as live class!!
what am I doing wrong ? what am I missing here?
If I want to add the weights to the BCEWithLogitsLoss what should I be doing?
As there are two arguemnts: weight and pos_weight and its not clear from the documentation which one to use and how.
For example, how is the network going to know, which class is positive and which one is negative (or in other words, which one is underrepresented and which one isnt) ?
3.is the same weight that is used with WerightedRandomSampler, can be used here with the loss?
Thanks a lot in advance.