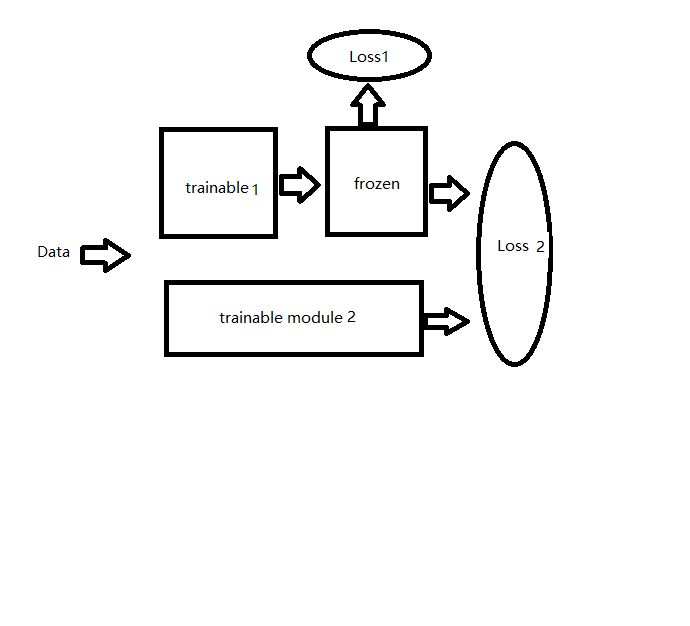
Sorry for my terrible drawing. But according to the above figure, I want to use 2 separate losses to update different modules in the entire network. The data flow is illustrated with arrows in the above figure, I hope to define a loss1 to only update “trainable 1”, and another term loss2 to only update “trainable 2”.
I apologize because I can’t paste our internal code here, so I have to briefly mention what I did:
I defined two optimizers: optimizer_1 (with parameters in “trainable 1” as trainable variables) and optimizer_2 (with parameters in “trainable 2” as trainable variables).
For each iteration of my training loop, I did something like this:
And crashed with the following error message # [RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time]
I am not sure if I should handle these two losses in this way. Could someone tell me what might be potentially wrong in my implementation, and how to fix it?
Thank you so much for the pointers.
Could you also comment on this “# [RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time]” error?
I tried to use splited parameters (i.e. trainable_1 assigned to optimizer1, and trainable_2 assigned to optimizer2, while there should not be overlap btw trainable_1 and trainable_2) for different optimizers to separate the two training flow. Where could be wrong to trigger this “Trying to backward through the graph a second time” error? BTW, I don’t fully understand this error, and will “retain_graph=True” be a correct fix in this case?
When you do backward pass, some of the values of the graph for the intermediate (non-leaf) nodes are freed. So, second pass over same nodes will trigger this error. To be able to proceed with second pass, you need to add parameter to loss1.backward(retain_graph=True)