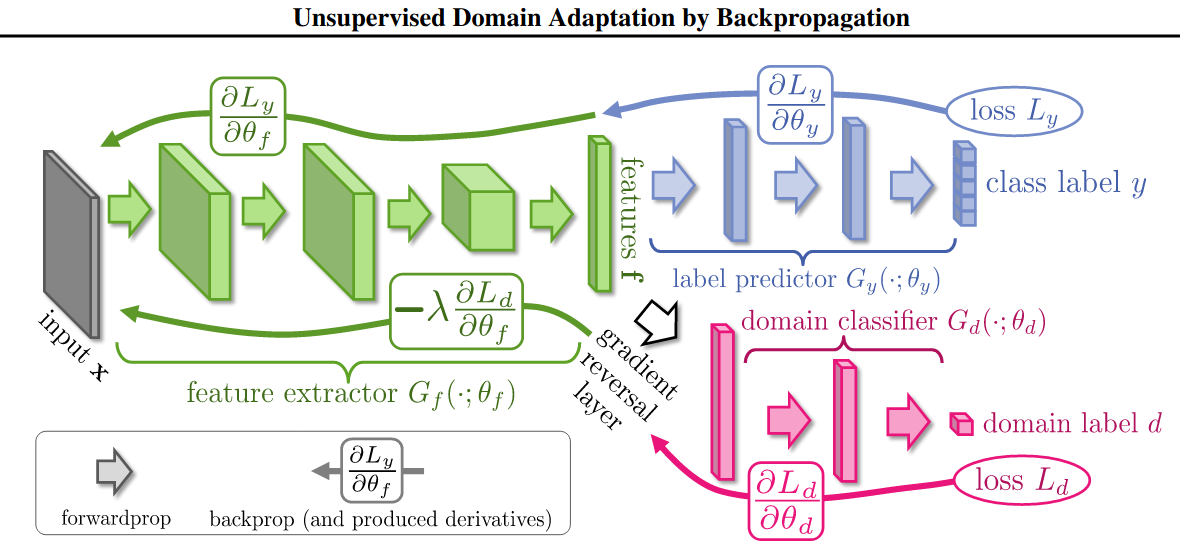
Gradients are accumulative in pytorch. This means unless you call optim.zero_grad() to set gradients to zero, gradients will keep accumulating.
You need to run both networks, backward pink using retain_graph=True. Then iterate through the gradients (for p in model.parameters(): p.grad *=-1)
Then backward blue loss and then use optimizer step and zero grad.
Note: I do highlight the ordering as if you backprop blue first you would be multiplying them by -1 too.