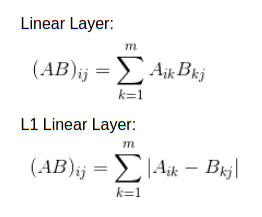Hello, I’m trying to implement a variation on a linear layer:
More specifically:
I have a model with an output (bsz x embed_dim).
I have an embed_matrix (embed_dim x num_classes)
I am trying to define an operation that takes in output and embed_matrix, and returns logits (bsz x num_classes)
With a linear layer, each element (i,j) in the logits corresponds to cosine similarity between the i’th embedding output by my model, and the j’th embedding in my embed_matrix.
I’d like to create a custom linear layer where instead of cosine similarity, each element corresponds to the L1 distance between two embeddings.
I’ve tried:
torch.abs(B - A.unsqueeze(-1)).sum(dim=-2)
however, this causes the memory to explode when a Linear layer handles the same matrices just fine.
Is there a way for me to compute this output with a similar memory/time as a linear layer?
AB = torch.zeros(bsz, num_classes).cuda()
for j in range(0, embed_dim, jbatch):
AB += torch.abs(A[:,j:j+jbatch].unsqueeze(-1) - B[j:j+jbatch,:]).sum(dim=-2)
where A is my model’s (bsz, embed_dim) output, B is my (embed_dim, num_classes) embedding layer, AB is my (bsz, num_classes) logits, and jbatch is a batching parameter to speed things up depending on available GPU memory.
as I loop through j, the allocated GPU memory keeps increasing by AB and I run out of memory quite fast
My guess is that whenever you unsqueeze, a new memory spot is assigned so I suggest you to unsqueeze A outside of the loop. Can you please a complete piece of code so that I can try myself?
import argparse
import torch
import time
from torch import nn
parser = argparse.ArgumentParser(description='L1 Linear Layer metrics')
parser.add_argument('--emsize', type=int, default=256,
help='size of word embeddings')
parser.add_argument('--vocabsize', type=int, default=35_000,
help='vocabulary size')
parser.add_argument('--bsz', type=int, default=80,
help='batch size')
parser.add_argument('--seqlen', type=int, default=50,
help='sequence length')
parser.add_argument('--jbatch', type=int, default=1,
help='batching when iterating over j')
parser.add_argument('--cuda', action='store_true',
help='use CUDA')
args = parser.parse_args()
print("instantiating model")
model = nn.LSTM(args.emsize, args.emsize)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
print("instantiating tensors")
I = torch.rand(args.seqlen,args.bsz,args.emsize)
H = (torch.rand(1,args.bsz,args.emsize),torch.rand(1,args.bsz,args.emsize))
B = torch.rand(args.emsize,args.vocabsize)
AB = torch.zeros(args.bsz*args.seqlen, args.vocabsize)
if args.cuda:
print("moving tensors and model to GPU")
t = time.time()
I = I.cuda()
B = B.cuda()
H = (H[0].cuda(), H[1].cuda())
AB = AB.cuda()
model = model.cuda()
print("time: ", time.time() - t)
print("model forward pass")
model.train()
A,_ = model(I,H)
A = A.view(args.bsz*args.seqlen, args.emsize)
print("Looping through emsize")
torch.cuda.synchronize()
t =- time.time()
for j in range(0, args.emsize, args.jbatch):
print(torch.cuda.memory_allocated())
AB += torch.abs(A[:,j:j+args.jbatch].unsqueeze(-1) - B[j:j+args.jbatch,:]).sum(dim=-2)
torch.cuda.synchronize()
t += time.time()
print("time: ", t)
Unfortunately, the allocated memory is constant in the script I provided.
I think it has to do with my trainable model parameters in my training script.
Taking the unsqueeze out of the for loop in the training script doesn’t solve the problem.
I can try to add a model/training loop to the script I shared with you.
My actual training script is quite dependency- and resource-heavy.
After broadcasting, you end up having a matrix of 4000 x 32 x 35000 which is more than 16 GiB which could not be saved even in the first step. I tried smaller batch sizes like 6 and it worked but you may need to check https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html.
I updated the code snippet to replicate the OOM issue during model training.
Also args.jbatch should be equal to one so that the matrix is 4000 x 1 x 35000.
That’s my mistake, I forgot to fix the default value (I was using 32x32 tiling before, instead of the 1xvocab_size tiling I’m using now).