Hello everyone! I’m new here. ![]() I’m an undergraduate student doing my research project.
I’m an undergraduate student doing my research project.
I’m not a native English speaker, so apologies to my weird grammar.
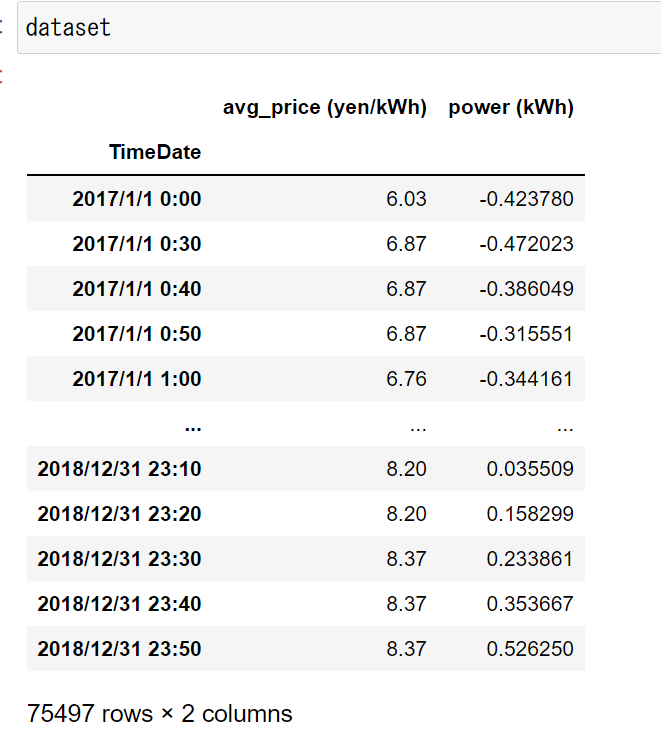
My research topic is about wind power prediction using an LSTM-NN and its application in the power trading. I used only the time-series date of wind power as parameters, so the power production is predicted based on the observed power production in the past.
Long story short, while trading, we care not only about the forecast accuracy, but also about the power price. When the price is low, a not-very-accurate forecast is acceptable. When the price is high, however, the wind power producer would prefer a highly accurate power production forecast.
In order to achieve this goal, I tried to update my loss function while training. I used the power price as weight factor and multiplied it with my MSE Loss function, so I defined my loss function as below:
def weighted_mse_loss(input, target, weight):
return (weight * (input - target) ** 2)
And tried to train my model like this:
# training
loss = 0
for i in range(epochs):
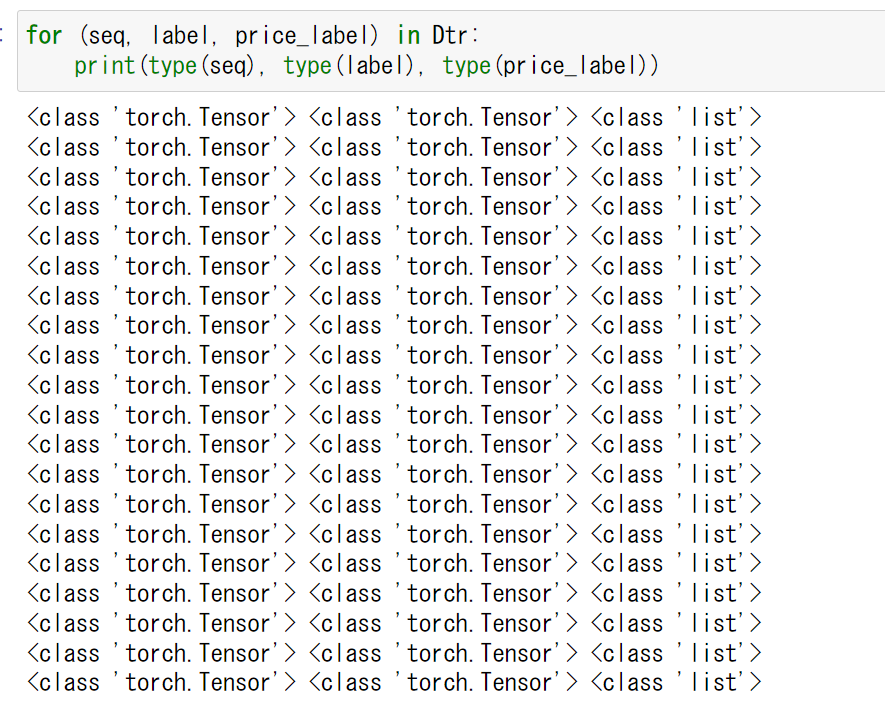
for (seq, label, price_label) in Dtr:
seq = seq.to(device)
label = label.to(device)
y_pred = model(seq)
loss = weighted_mse_loss(y_pred, label, price_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('epoch', i, ':', loss.item())
state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, path)
The sequence data I input was like this:
[(tensor([[-0.4238],
[ 0.7864],
[ 0.7743],
[ 0.6549],
[ 0.7195]]),
tensor([0.7324]),
[6.49]),
At any given time, for example, ([0.7324]) would be the true value of the forecast target, while the previous 5 values would be used for forecast. [6.49] would be the power price at that time which I directly used as the weights.
However, when I run my code, I had an error like this:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [118], in <cell line: 1>()
----> 1 train(LSTM_PATH)
Input In [117], in train(path)
18 label = label.to(device)
19 y_pred = model(seq)
---> 20 loss = weighted_mse_loss(y_pred, label, price_label)
21 optimizer.zero_grad()
22 loss.backward()
Input In [109], in weighted_mse_loss(input, target, weight)
1 def weighted_mse_loss(input, target, weight):
----> 2 return (weight * (input - target) ** 2)
TypeError: only integer tensors of a single element can be converted to an index
How could I fix that? Or is there a better way to update my MSE Loss function corresponding to the fluctuation of power price? I’m an EE student so I’m not very good at coding ![]()