criterion = torch.nn.MSELoss()
lr = 1e-4
weight_decay = 0 # for torch.optim.SGD
lmbd = 0.9 # for custom L2 regularization
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
for data in test_loader:
images, labels = data
test = Variable(images.view(tuple(images.shape)))
outputs = model(test)
true_y = labels.max(1)[1]
predicted_y = outputs.max(1)[1]
# Compute and print loss.
loss = criterion(predicted_y, true_y)
optimizer.zero_grad()
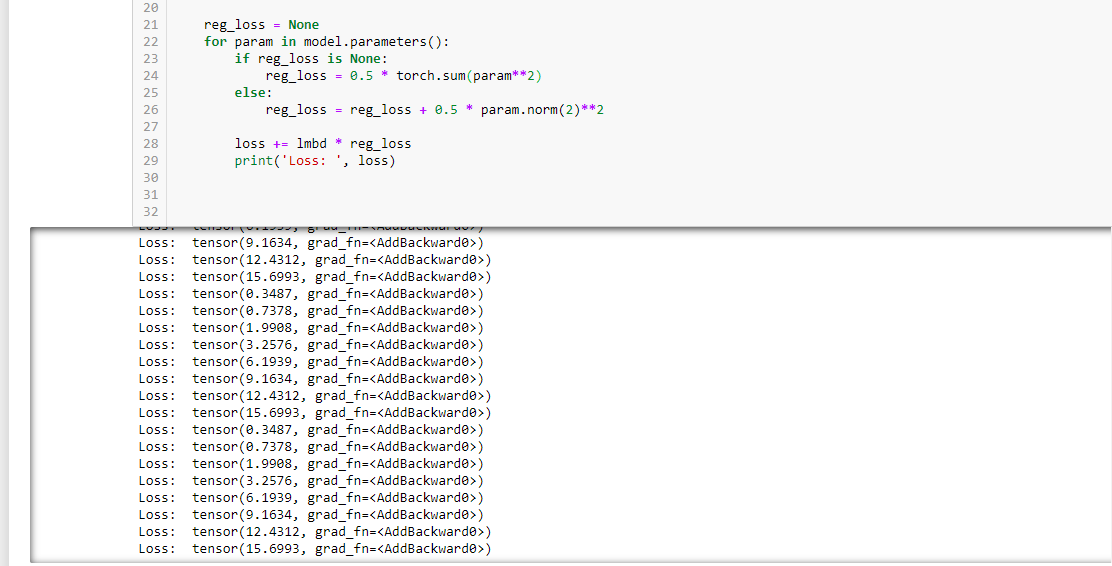
reg_loss = None
for param in model.parameters():
if reg_loss is None:
reg_loss = 0.5 * torch.sum(param**2)
else:
reg_loss = reg_loss + 0.5 * param.norm(2)**2
loss += lmbd * reg_loss
print('Loss: ', loss)
but getting below error
RuntimeError: _thnn_mse_loss_forward not supported on CPUType for Long
Oh, I forgot to say which is weird that you are not getting any error. torch.max(tensor, dim) returns a tuple of values and corresponding indices. So change your code in this way:
Finally, if you want to get loss values and aggregate them or anything that only related to its value as you said, you must use loss.item().
Anything, If you want to just print the loss value and do not change it in anyway, use .item() and it will return the corresponding value. In your case, just .item() to the print function.
But if you want to change the loss itself, for instance, merging two different losses by weighted sum, something like loss = 10*loss1 + 5*loss2, you should not use .item() because you will lose grad_fn which is your backward function.