Hello. I’m currently working on spherical convolutional network topic. Right now I’m trying to develop a new kind of kernel used for the convolutional layer.
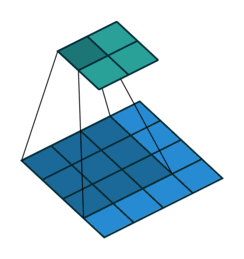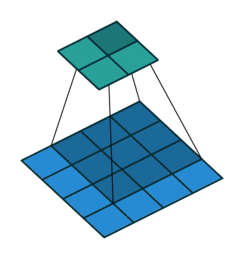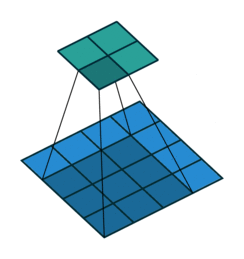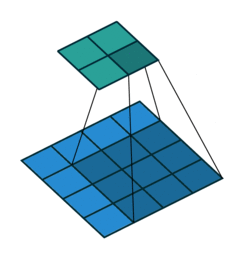
The usual kernel is 3x3 matrix. But for spherical images, after being projected onto a plane using equirectangular projection, there will be distortion. So I want to define the kernel as a spherical cap and project it on plane according to its position.
For example, the kernel at different positions of the sphere perspective to the panorama pictures will look like this:
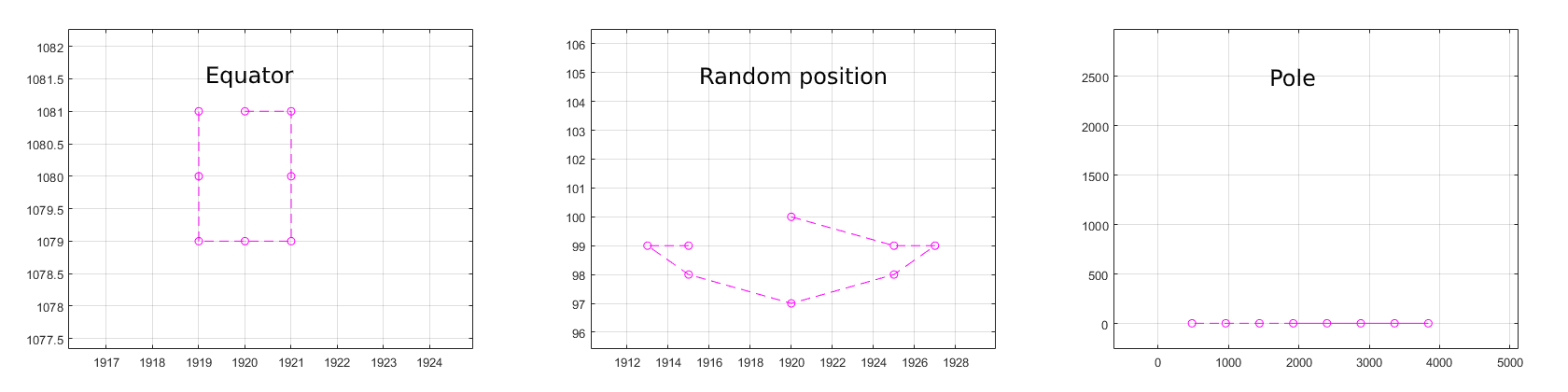
Is there any way to determine the shape of the kernels in these ways? I have already had the whole coordinate of the points in every case. I would very appreciate any help and information.
Thank you guys very much!