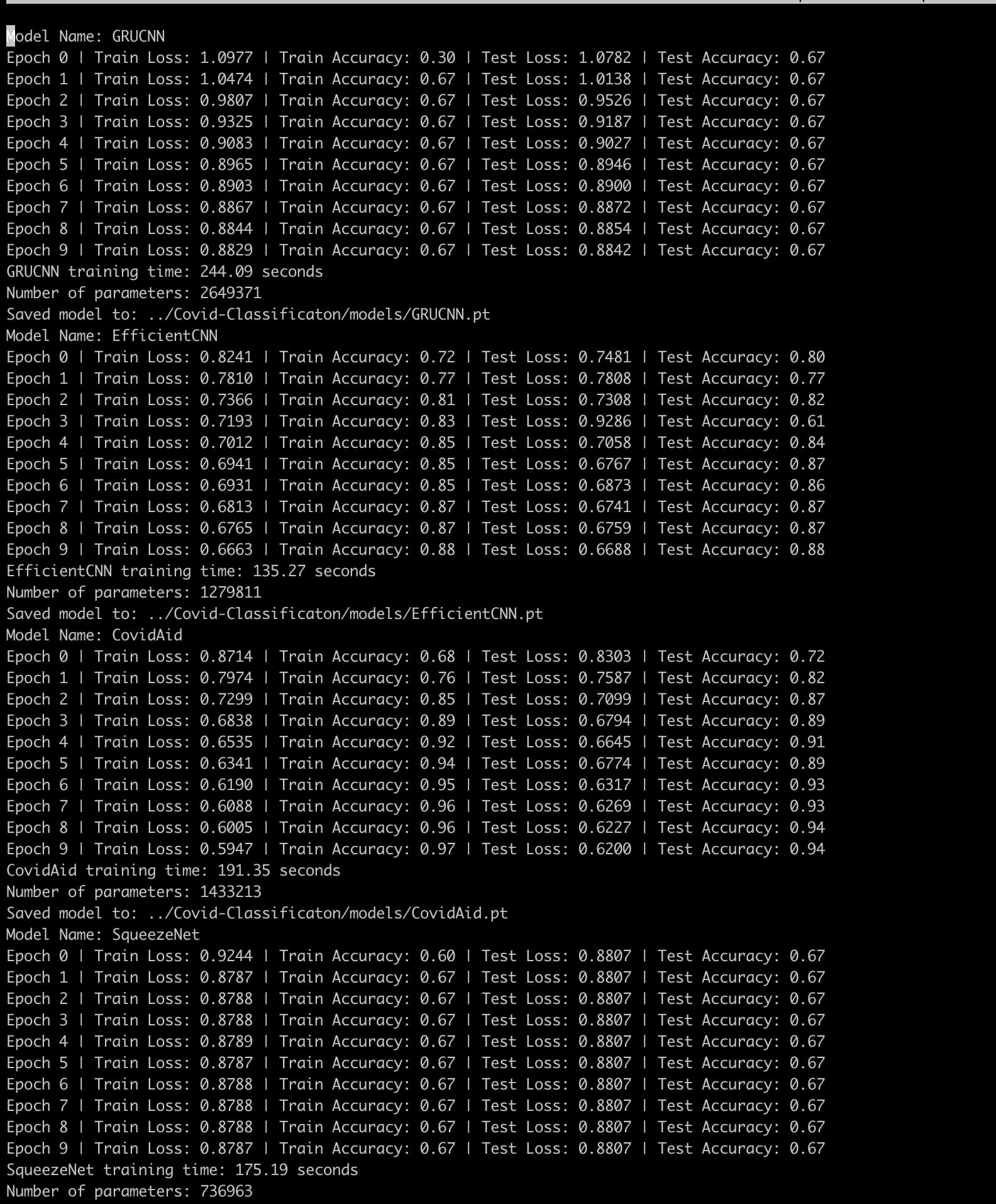
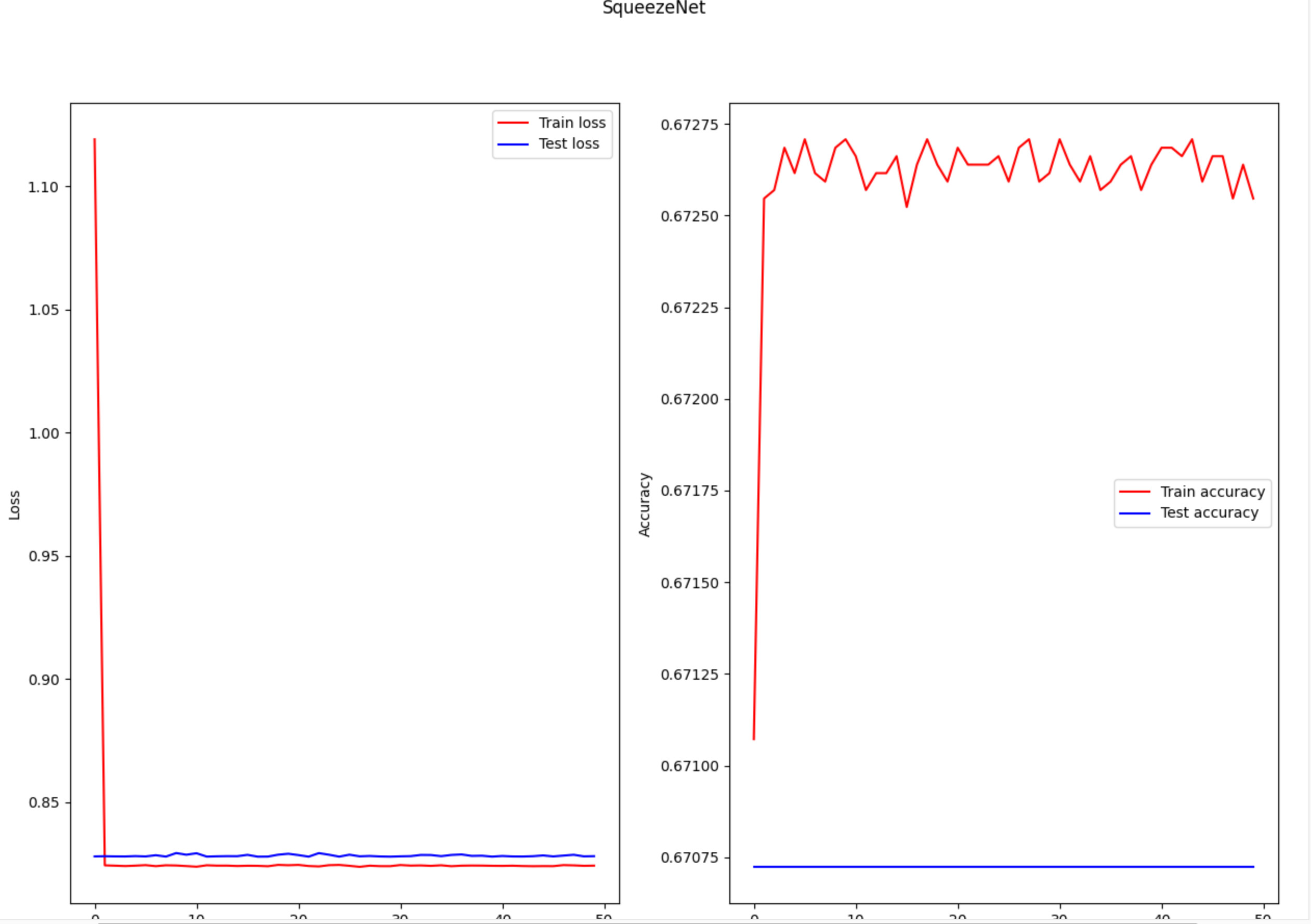
Thanks for the feedback, on a relevant note I’ve tested my model with just a random tensor and the outputs of the tensor’s are really similar. When I tested it with other models, the outputs were vastly different. Can you give me some advice on how to fix this?
""""
Squeeze Net takes input of 224 instead of 256, so have to scale it accordingly
"""
import torch
import torch.nn as nn
class FireModule(nn.Module):
"""
s1x1: number of filters in squeeze layer (all 1x1)
e1x1: number of 1x1 filters in expand layer
e3x3: number of 3x3 filters in expand layer
s1x1 > (e1x1 + e3x3)
"""
def __init__(self, in_channels, s1x1,e1x1,e3x3,):
super().__init__()
self.squeeze = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=s1x1, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
)
self.expand_e1x1 = nn.Sequential(
nn.Conv2d(in_channels=s1x1, out_channels=e1x1, kernel_size=1, stride=1, padding=0),
nn.ReLU(inplace=True),
)
self.expand_e3x3 = nn.Sequential(
nn.Conv2d(in_channels=s1x1, out_channels=e3x3, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.squeeze(x)
y = self.expand_e1x1(x) # 64
z = self.expand_e3x3(x) # 64
return torch.cat((y, z),dim=1)
class SqueezeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv_1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=3, stride=1, padding=1)
self.bn_1 = nn.BatchNorm2d(96)
self.conv_10 = nn.Conv2d(in_channels=512, out_channels=3, kernel_size=1, stride=1, padding=2)
self.relu = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, ceil_mode=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, ceil_mode=True)
self.maxpool_8 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, ceil_mode=True)
self.fireModule_2 = FireModule(96, 16, 64, 64)
self.fireModule_3 = FireModule(128, 16, 64, 64)
self.fireModule_4 = FireModule(128, 32, 128, 128)
self.fireModule_5 = FireModule(256, 32, 128, 128)
self.fireModule_6 = FireModule(256, 48, 192, 192)
self.fireModule_7 = FireModule(384, 48, 192, 192)
self.fireModule_8 = FireModule(384, 64, 256, 256)
self.fireModule_9 = FireModule(512, 64, 256, 256)
self.dropout = nn.Dropout(p=0.5)
self.avgpool_10 = nn.AvgPool2d(4)
self.softmax = nn.Softmax()
self.linear = nn.Linear(192,3)
def forward(self, x):
x = self.conv_1(x)
x = self.bn_1(x)
x = self.relu(x)
x = self.maxpool_1(x)
x = self.fireModule_2(x)
x = self.fireModule_3(x)
x = self.fireModule_4(x)
x = self.maxpool_4(x)
x = self.fireModule_5(x)
x = self.fireModule_6(x)
x = self.fireModule_7(x)
x = self.fireModule_8(x)
x = self.maxpool_8(x)
x = self.fireModule_9(x)
x = self.dropout(x)
x = self.conv_10(x)
x = self.relu(x)
x = self.avgpool_10(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
x = self.softmax(x)
return x
Test with random tensor
torch.manual_seed(42)
test_img = torch.rand(32, 3, 224, 224)
model = SqueezeNet()
print(model(test_img).shape)
print(model(test_img))
When I run the above code I get this, where all of the outputs are similar:
tensor([[0.3204, 0.3256, 0.3539],
[0.3203, 0.3257, 0.3540],
[0.3201, 0.3265, 0.3534],
[0.3200, 0.3249, 0.3551],
[0.3204, 0.3251, 0.3545],
[0.3196, 0.3256, 0.3548],
[0.3194, 0.3260, 0.3546],
[0.3200, 0.3264, 0.3536],
But when I run another model I get this:
tensor([[0.4194, 0.1613, 0.4194],
[0.8631, 0.0101, 0.1268],
[0.3775, 0.2676, 0.3550],
[0.0022, 0.0015, 0.9963],
[0.1903, 0.6193, 0.1903],
[0.5297, 0.2212, 0.2491],
[0.6913, 0.1241, 0.1846],
[0.7054, 0.1266, 0.1680],
[0.1698, 0.6705, 0.1597],