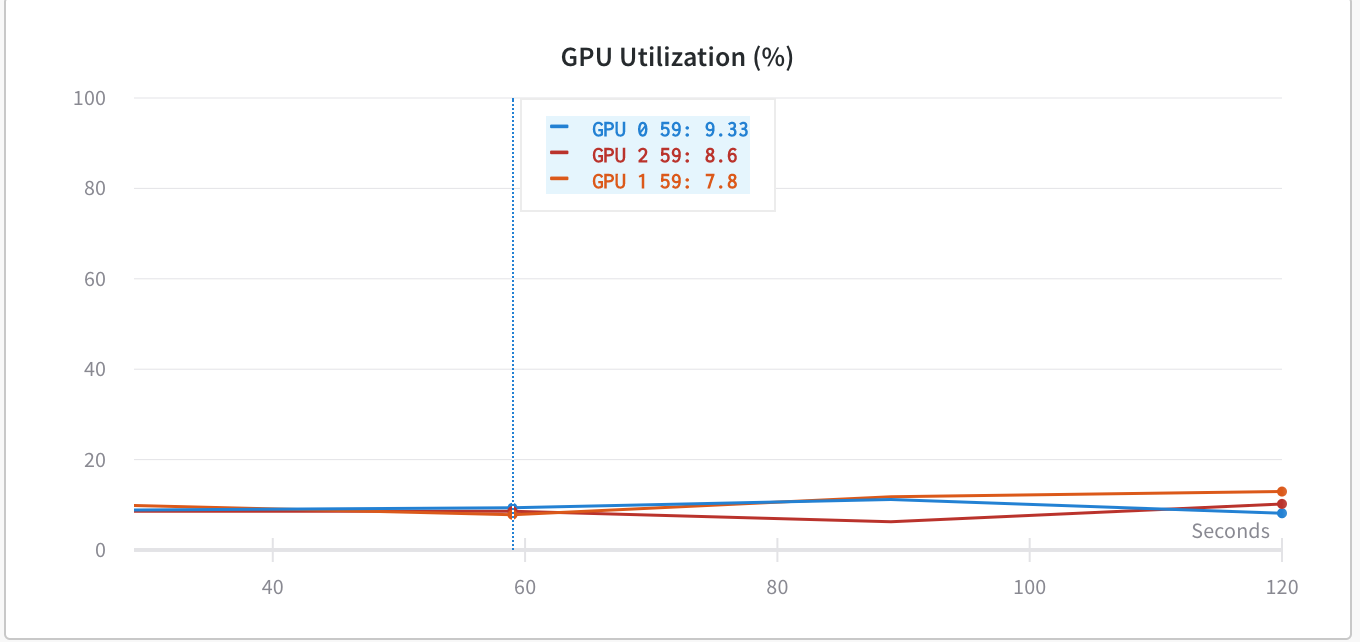
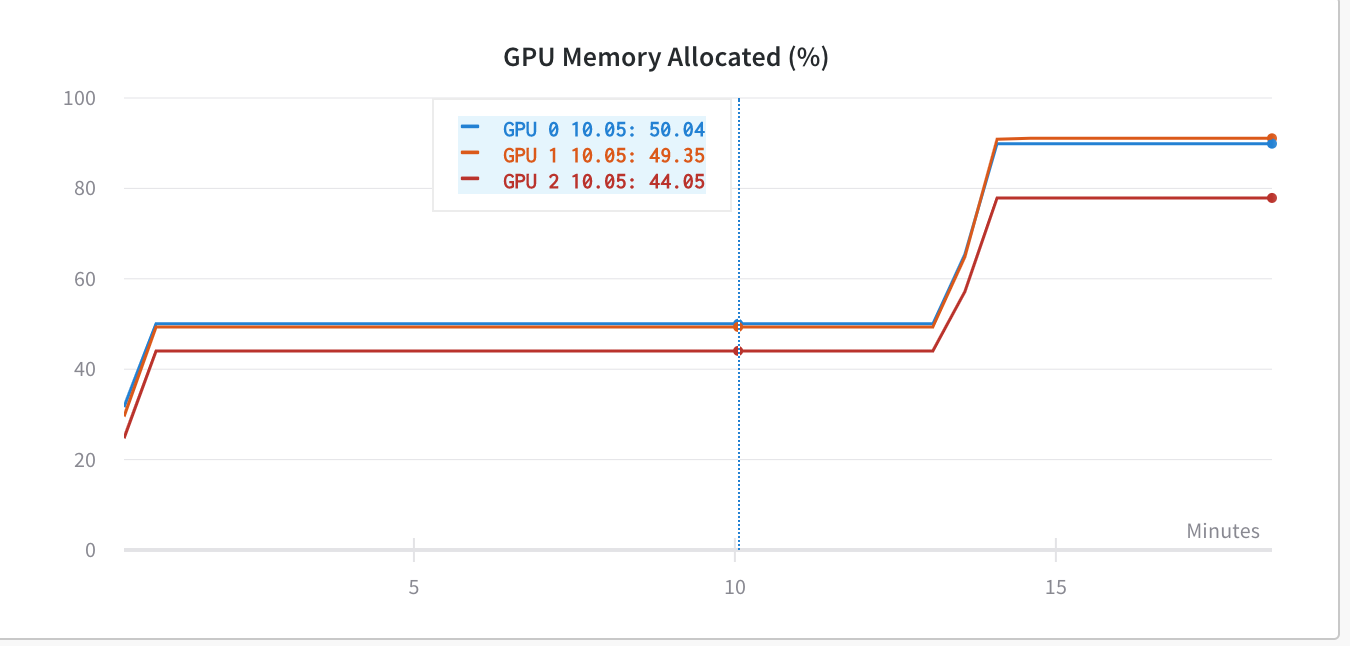
You would have to profile the code and isolate the potential bottleneck.
Since the GPU utilization is low, your data loading might be the bottleneck. This post explains potential workarounds and best practices for this issue.
Thanks a lot for replying.
I tried to profile the code but it kept on running and was not printing anything required. I posted about it here - Torch.utils.bottleneck keeps on running
I tried to increase the num_Workers from 1 to more than 1 but I encountered the error - Training crashes due to - Insufficient shared memory (shm) - nn.DataParallel
I tried solving it using the below post - but I have enough memory according to this solution Training crashes due to - Insufficient shared memory (shm) - nn.DataParallel