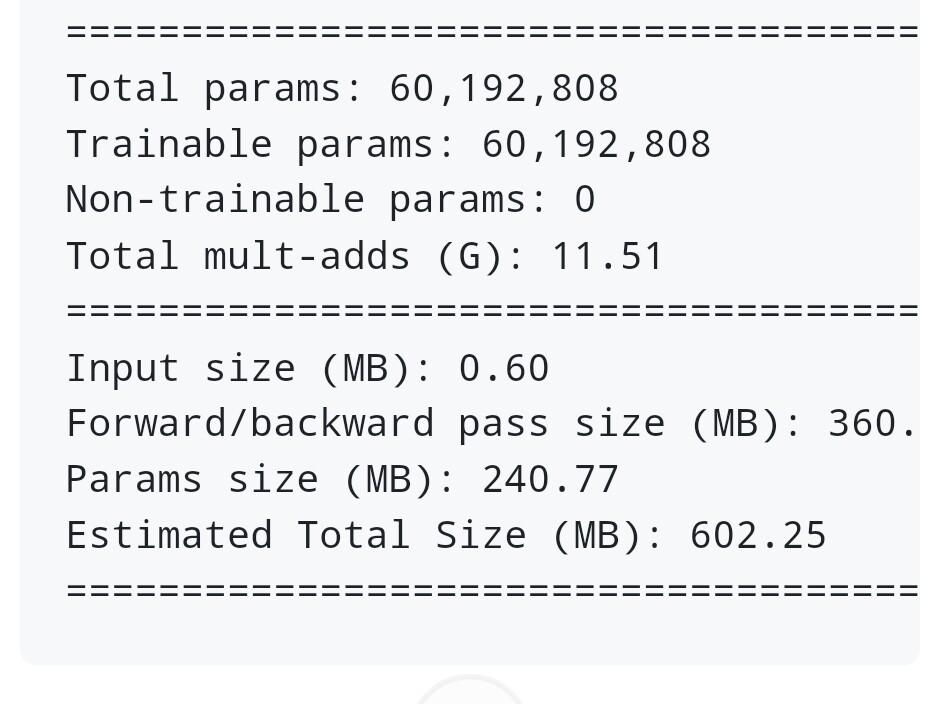
Multiply-adds are used as shorthand for the total number of operations in the model as popular layers such as convolution and linear layers multiply weights with inputs and then add the results of the multiplication (possibly with a bias). A single multi-add would be e.g., a scalar wx + b and would correspond to two floating point operations. So the mult-adds would roughly be 1/2 the total number of floating point calculations per image.
Given that the total size is roughly the sum of the params + forward/backward pass size. I assume that this is roughly the total amount of memory needed to train the model.
However, the real number in practice is a bit tricker to obtain as there could be effects such as memory fragmentation that increase the total required memory needed to train the model. Also note that if you are just running inference without training you shouldn’t need the “total size” worth of memory as you can wrap the model execution with torch.no_grad(): to discard intermediate activations during the forward pass.