I was doing inference for a instance segmentation model. I found the GPU memory occupation fluctuate quite much. I use both nvidia-smi and the four functions to watch the memory occupation: torch.cuda.memory_allocated, torch.cuda.max_memory_allocated, torch.cuda.memory_reserved, torch.cuda.max_memory_reserved. But I have no idea about the minimum memory the model needs.
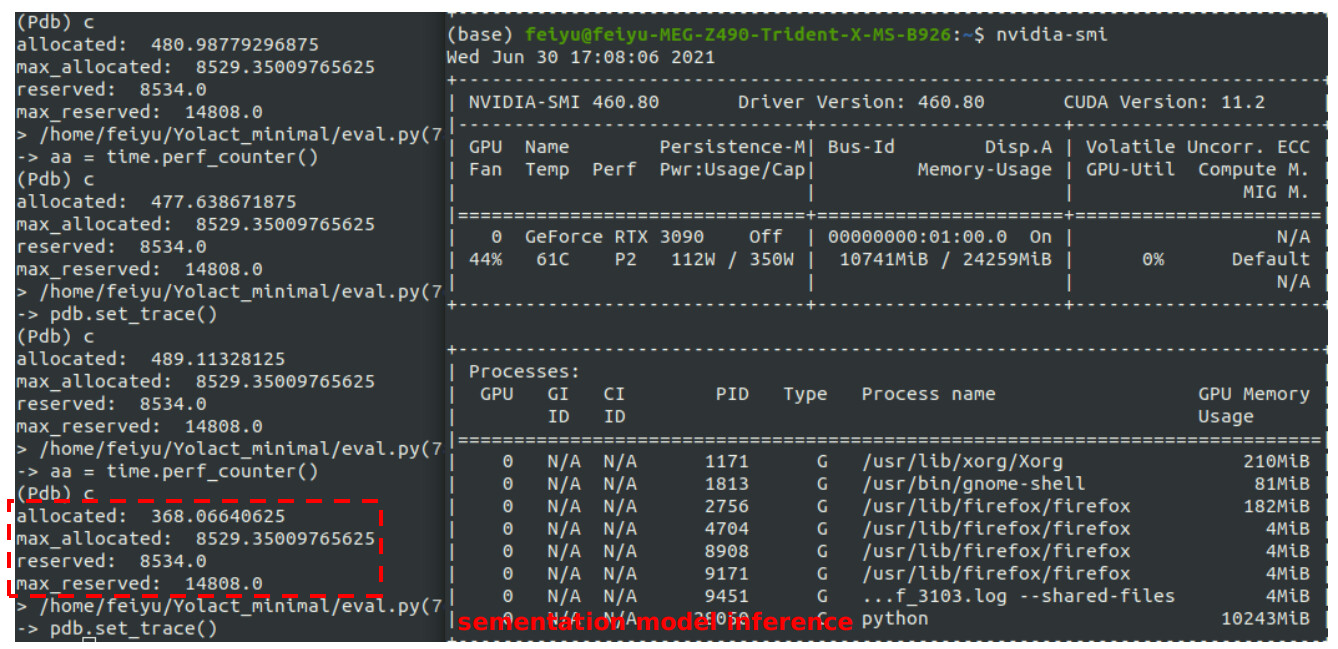
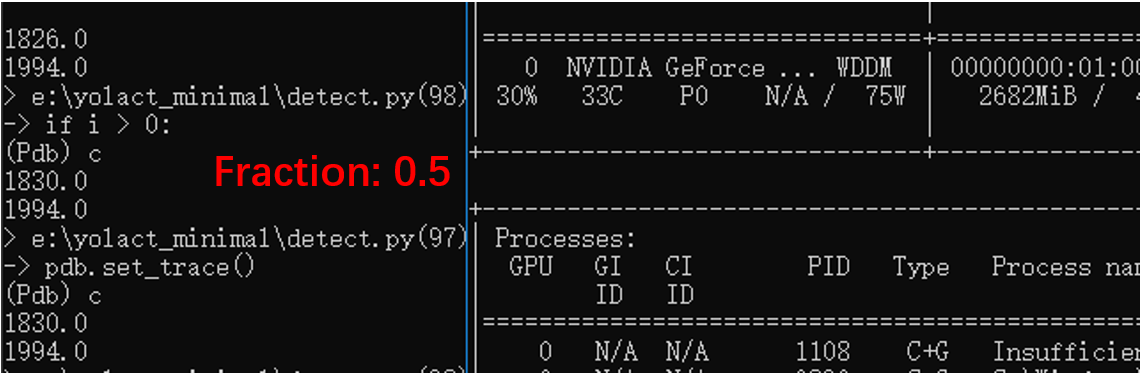
If I only run the model in my GPU, then the memory usage is like:
5GB memory is occupied for the segmentation model.
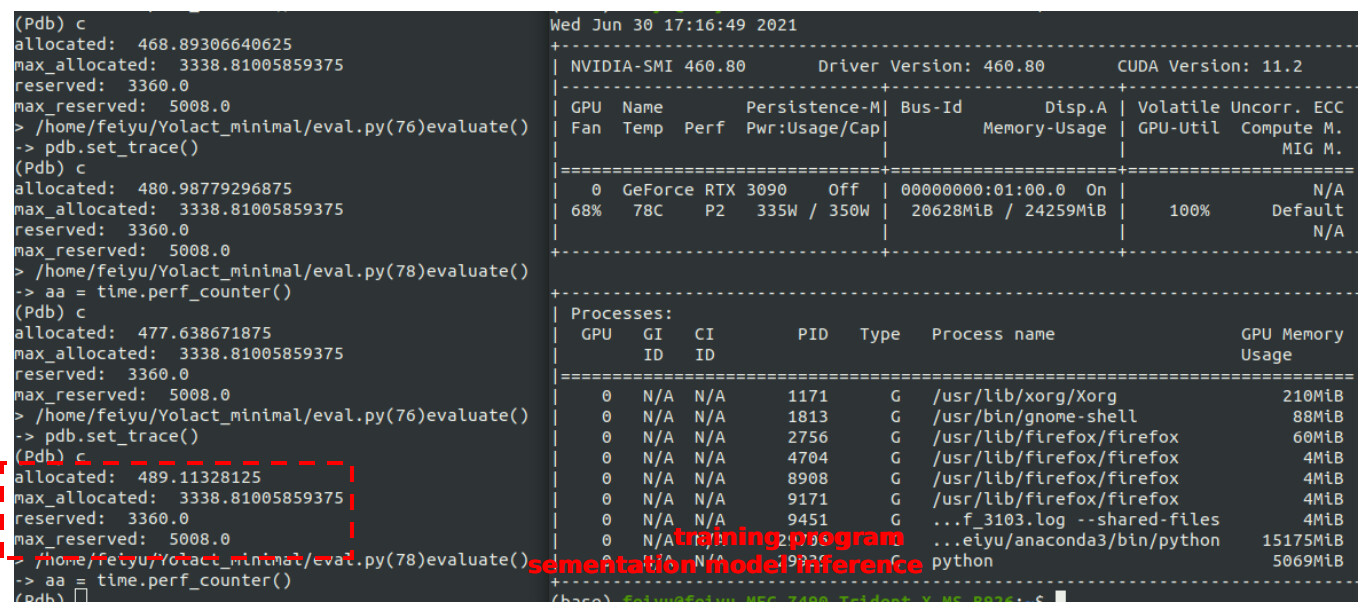
If I run another training program with larger batch size to use some more memory first, and then run the segmentation model’s inference, then the memory usage is like:
With 2437MB memory, the model can also run.
So I am confused about the memory usage. Even with the torch.cuda.memory... like function, I can’t know how much memory my model needs. It’s always changing. It’s hard for me to choose a suitable memory GPU to deploy my model.
In general this can be kind of tricky to reason about, because reserved memory might not always be fully used (e.g., reserved ahead of time to speed up future allocations) and also because allocations happen in blocks and fragmentation means that reserved memory > allocations.
I think the closest thing you can get to a guarantee on the required memory would be to use set_per_process_memory_fraction: torch.cuda.set_per_process_memory_fraction — PyTorch 1.9.0 documentation and to reduce this amount until the model cannot run to see how much memory it needs. For example, you can just keep reducing the fraction, and use the (fraction * total gpu memory) amount to get a good idea of the requirements under normal conditions.
Finally, after getting this estimate, I would recommend provisioning at least 100-200MiB of headroom because the memory usage of non-model things like the PyTorch/cuBLAS/cuDNN libraries may grow over time.
@eqy Thank for the advice. I did some tests again with torch.cuda.set_per_process_memory_fraction.
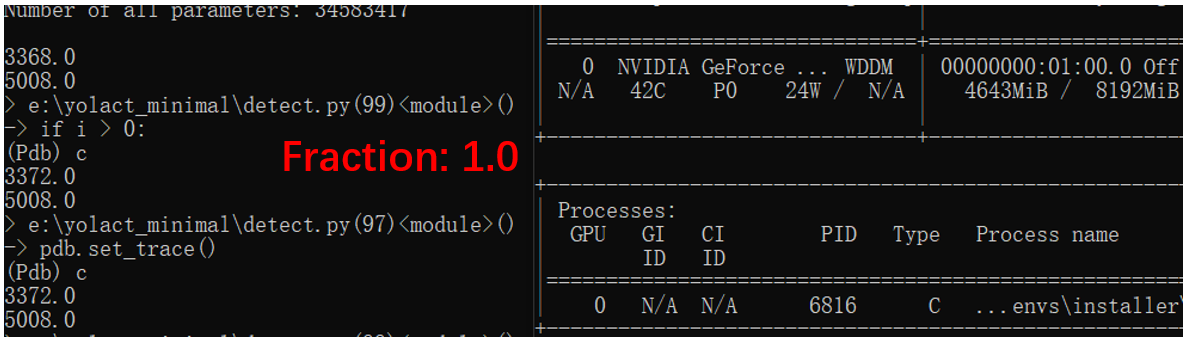
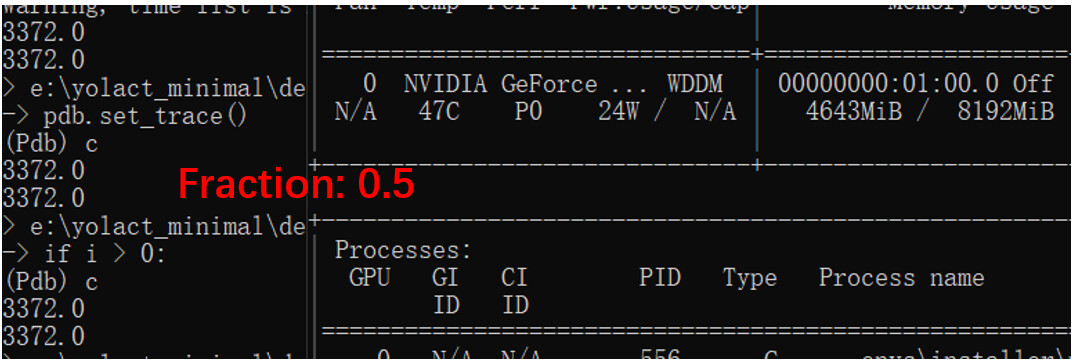
I run the segmentation model inference on two GPUS: a 4G memory GPU and a 8G memory GPU. And I set different fractions as you told to test.
The 4G GPU:
Both the two GPUs encountered “cuda out of memory” when the fraction <= 0.4.
This is still strange. For fraction=0.4 with the 8G GPU, it’s 3.2G and the model can not run. But for fraction between 0.5 and 0.8 with the 4G GPU, which memory is lower than 3.2G, the model still can run. And seems torch.cuda.set_per_process_memory_fraction can only limit the pytorch reserved memory. The reserved memory is 3372MB for 8G GPU with fraction 0.5, but nvidia-smi still shows 4643 MB. Some memory did not return to the OS.
Interesting, is the script doing some kind of runtime batch size adjustment after checking the amount of GPU memory? I would be surprised if the batch size is the same across GPUs with different memory usage unless something like precision of the data types is changed.
Yes, I don’t think there is a user-facing controllable way (or even a PyTorch controllable way short of rebuilding the libraries) to change the remaining 1GiB+ of memory usage as this is dedicated to the library code (native kernels, cuDNN, cuBLAS, etc.) that cannot be removed.
@eqy I was running a model inference and the batch size are both 1. The code on two GPUs are exactly the same. I just copied one to the other. And there’s no other program running or batch size adjustment. I found the memory usage depends on the GPU type. And I found torch.cuda.empty_cache() can sometimes get the minimum usage. But it sometimes doesn’t work.
I think I know why the memory usage is high. I used cudnn.benchmark = True in my code. This caused a high memory usage. For the code below:
import torch
import torch.backends.cudnn as cudnn
import pdb
from torchvision.models import resnet50
net = resnet50()
net.eval()
# cudnn.benchmark = True
net = net.cuda()
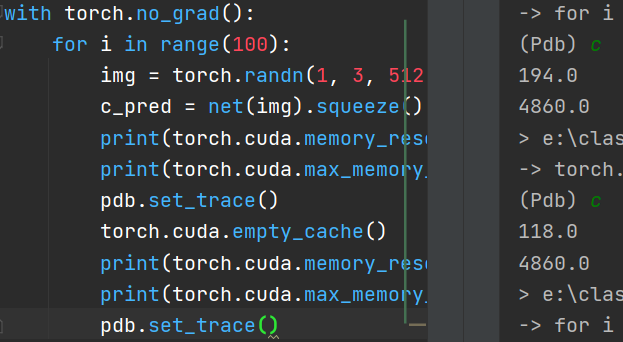
with torch.no_grad():
for i in range(100):
img = torch.randn(1, 3, 512, 512).cuda()
c_pred = net(img).squeeze()
print(torch.cuda.memory_reserved()/1024/1024)
print(torch.cuda.max_memory_reserved()/1024/1024)
pdb.set_trace()
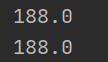
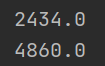
The memory usage is:
And if I uncomment the cudnn.benchmark = True, the memory usage is:
That’s quite too much memory used. Then I used torch.cuda.empty_cache(), the memory usage became normal.
I’m a bit confused by what you mean here, as cudnn.benchmark shouldn’t ever increase the memory requirements of your model. If there is more memory available, the peak usage can definitely be higher as benchmark will try algorithms that require a larger workspace (temporary global memory). However, this shouldn’t affect the memory requirements as decreasing the available memory will filter out the algorithms that need a larger workspace.
I just comment and uncomment cudnn.benchmark=True to test the memory usage. And I found they differ far. I don’t know the exact mechanism behind it.
Here is an answer from someone else.
Right, but the fastest available should be constrained by the available memory. So if you decrease the allowed memory, benchmark=True should never surpass it:
Yes, I did a test, benchmark=True never surpass the allowed memory. I am just surprised about the max_memory_reserved. Doing inference on a 24G memory GPUwith benchmark=False only needs about 1.2G memory. However, the max_memory_reserved and the nvidia-smi memory usage goes to almost 12G with benchmark=True. Now I decide to never use it.