greetings i tested alot of things:
i trained the models speretaly and it seems they work without the multitask.
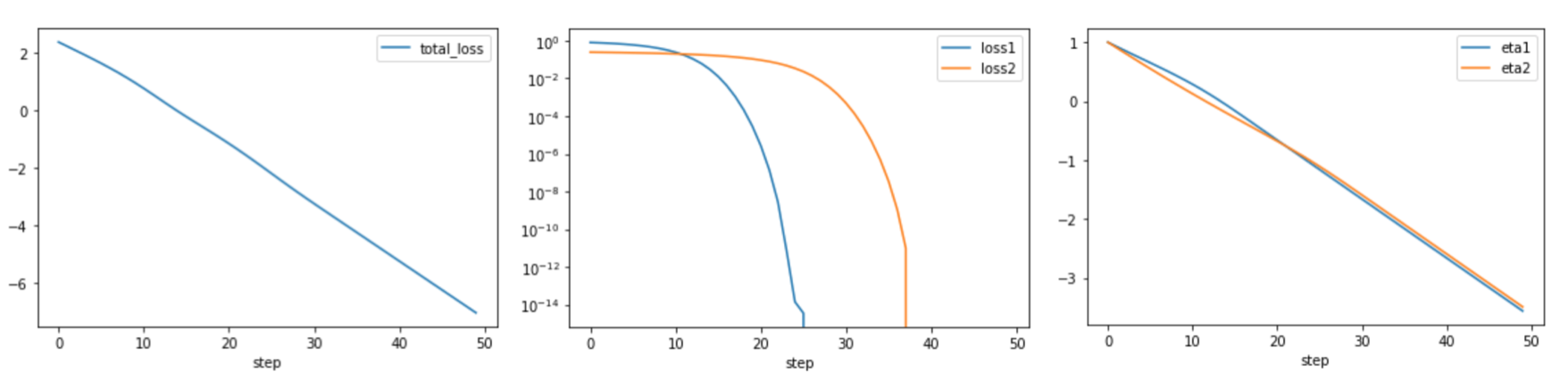
I also took your advice and did not make a custom initialization. It works good but the problem with multitask is still there:
I think its because of the loss function.
Currently i just add the loss together, put the sum in backprop. But that doesnt seem to work. Is there a good tutorial or way to make the loss for multitask pretrained models?
I integrated the Multilossfunction from this thread:
But it still does not work. I can train them seperately but together they dont work (one task accurcay rises, while the other stays low)
I use crossentropy for both.
model = Resnet50_multiTaskNet().to(device)
criterion = [nn.CrossEntropyLoss(), nn.CrossEntropyLoss()]
def loss_fn1(x, cls):
return 2 * criterion[0](x, cls)
def loss_fn2(x, cls):
return 2 * criterion[1](x, cls)
mtl = MultiTaskLoss(model=model,
loss_fn=[loss_fn1, loss_fn2],
eta=[1.0, 1.0]).to(device)
optimizer = optim.Adam(mtl.parameters())
class Resnet50_multiTaskNet(nn.Module):
def __init__(self):
super(Resnet50_multiTaskNet, self).__init__()
self.model = models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
for param in self.model.parameters():
param.requires_grad = False
self.fc_artist = nn.Linear(2048, class_length ['artist']).to(device)
self.fc_style = nn.Linear(2048, class_length ['style']).to(device)
def forward(self, x):
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
x = self.model.layer1(x)
x = self.model.layer2(x)
x = self.model.layer3(x)
x = self.model.layer4(x)
x = self.model.avgpool(x)
x = x.view(x.size(0), -1)
x_artist = self.fc_artist(x)
x_style = self.fc_style(x)
return x_artist, x_style
#multitaskloss
class MultiTaskLoss(nn.Module):
def __init__(self, model, loss_fn, eta) -> None:
super(MultiTaskLoss, self).__init__()
self.model = model
self.loss_fn = loss_fn
self.eta = nn.Parameter(torch.Tensor(eta))
def forward(self, input, targets) -> Tuple[torch.Tensor, torch.Tensor]:
outputs = self.model(input)
loss = [l(o,y) for l, o, y in zip(self.loss_fn, outputs, targets)]
total_loss = torch.stack(loss) * torch.exp(-self.eta) + self.eta
return loss, total_loss.sum(), outputs # omit 1/2
Anyone has an idea why?