if self.reduction == 'sum':
multi_task_losses = multi_task_losses.sum()
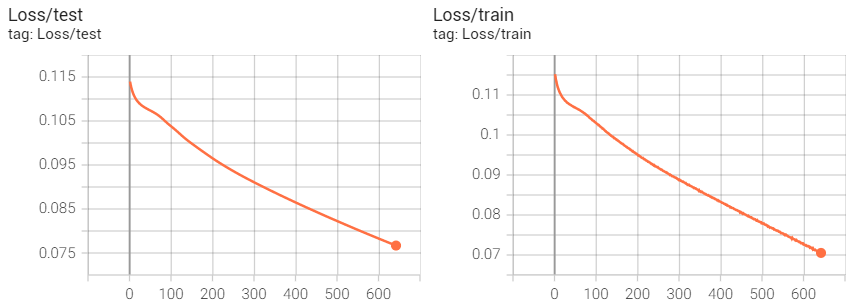
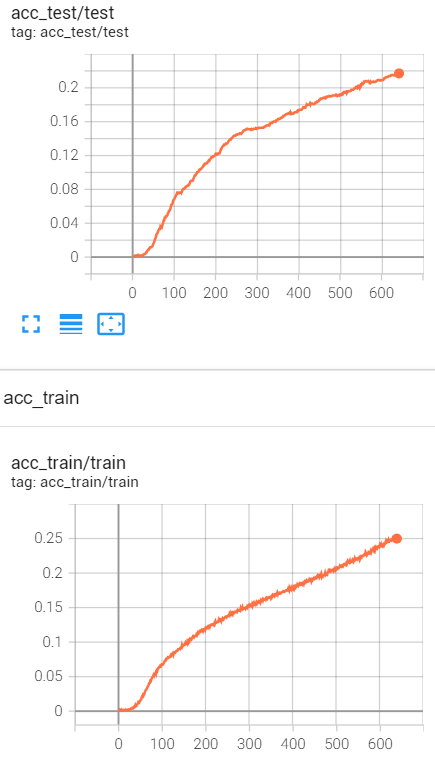
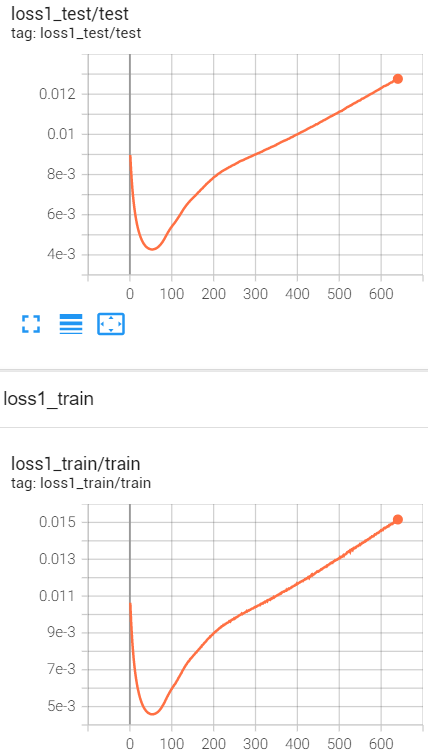
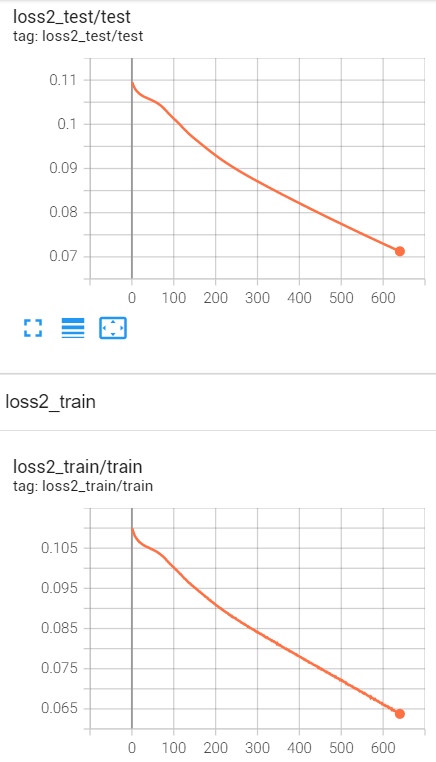
With the total loss decreasing, the mse loss went up and the cross entropy loss declined. And the accuracy is not satisfactory. Can anybody give me some clues to improve that?
total loss:
Your MultiTaskLoss is a scheme to “learn” the appropriate relative
weighting for the two losses for the two dissimilar tasks – regression
and classification – that you are training your network to perform at
the same time.
I have three comments:
self.log_vars is a “learnable” parameter that is to be trained by your
optimizer. Make sure that you have added self.log_vars to whatever
optimizer you are using. Otherwise it won’t get updated, and you’ll just
be summing your two losses together, which could easily not be giving
enough weight to your “mse loss.”
It’s possible that your use case isn’t well suited to the way that MultiTaskLoss works. I generally advise trying the “simple” approach
first, even if the fancier approach should (and maybe even does) work
better. Try leaving out MultiTaskLoss and just sum your two losses
together with a weighting factor. Can you get your network to train with
both losses going down reasonably by adjusting your weighting factor
appropriately? (In essence, you would be doing by hand what MultiTaskLoss is supposed to do for you automatically.)
Your training looks fine. I don’t see any evidence of your cross-entropy
loss or accuracy plateauing or of overfitting. The only problem is that
your mse loss starts going up after falling initially. This suggest that your
mse loss is not weighted heavily enough in your total loss. This could
happen if you failed to include self.log_vars in your optimizer (or if MultiTaskLoss just doesn’t work for your use case). But it could also
happen if it takes a while for self.log_vars itself to train properly.
Your charts run for about 650 “somethings,” which I imagine might be
epochs, For many substantive problems, this isn’t very much training
at all, so you might try training significantly longer (after verifying that self.log_vars is being updated by your optimizer). Perhaps the
relative loss weight will start to be learned properly, your mse loss
will be weighted more heavily, and mse loss will start going down.
(And even if your regression problem doesn’t train well, maybe your
classification problem will continue to train effectively and your
classification accuracy will become “satisfactory.”)