Thank you. In your code snippet, what is “data”? I mean, what form is it in/ how is it initialized?
The images are gray scale - but the raw images are 1000x1000 so the full dataset is more than 20 GB. During training, they’re subsampled down to 32x32, though. Maybe I can figure out how to do this once on the CPU, then send the subsampled data to the GPU. Would that work?
data and target would be returned by the DataLoader in the typical loop:
for data, target in loader:
data = data.to('cuda')
target = target.to('cuda')
Ah OK, that would change the memory footprint to 25000*32*32*4/1024**2 = 97.7MB.
Yes that should work. You could iterate the Dataset once, loading and resizing each sample in its __getitem__ method and appending these samples to a list.
Once this is finished, you can use data_all = torch.stack(data_list) to create a tensor and save it via torch.save.
In your training, you would reload these samples using torch.load and push it to the device.
Note however, that this approach would limit your ability to apply data augmentation, as most of the torchvision.transforms are implemented to PIL.Images, which are using numpy arrays under the hood.
Can the images be sent to the gpu as PIL? (Rather than as tensors?) Basically, I’d split the transformation pipeline - subsample the PIL, send to the gpu, do the augmentation and tensor conversion on the gpu. Not that I really know how to do this yet ;^) but I’d like to know if this is a feasible approach.
Sorry if my questions are basic. It does seem that this issue of really large datasets must come up all the time in ML applications.
That’s unfortunately not possible, as PIL uses numpy arrays under the hood, which cannot be pushed to the GPU.
You could however, grab the numpy array, transform it to a tensor, and push the tensor to the device:
I just wanted to bring some closure to this topic by reporting that your suggestions were successful. I used my old dataset, based on datasets.ImageFolder, to enumerate, subsample and transform all the training images. I concatenated all images (over 57,000 instances, but now only 32x32), and saved using torchscript (also saving the labels in a corresponding text file).
Then I sub-classed TensorDataSet to read these two files and return individual 32x32 tensors and labels in the item method. Now I can send each batch to the GPU as I originally wanted, with very low overhead.
Previously, each epoch took almost twenty minutes. Now an epoch takes about ten seconds.
The one downside is that the contrast and brightness adjustments from the color jitter transform are the same for every epoch (because they are applied before the subsampled tensors are stored). However, I could get around this by creating new preprocessed input files every few hundred epochs. (This is a very challenging discrimination and I expect training will take many iterations.)
I don’t know how large each image is, but assuming you are using images of the shape [3, 224, 224] , a dataset of 25000 images will takes approx. 25000*3*224*224*4/1024**3 = 14GB of GPU memory.
Why the 4 before the conversion to Gb? I was expecting to see a 32 given that torch tensors are normally written in float32. Would you please give me a hint?
Thank you so much everyone for your suggestions, it worked for me as well.
I have an autoencoder dataset with small images where I uploaded the images, did image and tensor transforms, and put them in a list in init. I used the default dataloader. The resulting time reduction is 95%
Trying this out, but using a Dataset rather than a TensorDataset – reason being I’m reshaping some of the tensors within the Dataset’s __getitem__ method. All source tensors are pushed to the GPU within Dataset __init__, and the resultant reshaped and fetched tensors live on the GPU. I’d like reassurance that the fetched tensors are truly views of slices of the source tensors, or at least that Dataset or Dataloader aren’t temporarily copying data to the CPU and back again. Any advice?
Hi, a bit late here, but I would not worry about data being copied back and forth between devices unless you specifically use a to(device) call. If that was a problem, backpropagation across multiple layers wouldn’t work very well
For views of tensors, from the docs…
PyTorch allows a tensor to be a View of an existing tensor. View tensor shares the same underlying data with its base tensor. Supporting View avoids explicit data copy, thus allows us to do fast and memory efficient reshaping, slicing and element-wise operations.
So as long as you are actually doing a view… I would believe the docs. The reason is, the docs specifically tell you when the function is not assured to create a view… ie under reshape…
torch.reshape (input , shape ) → Tensor
Returns a tensor with the same data and number of elements as input , but with the specified shape. When possible, the returned tensor will be a view of input . Otherwise, it will be a copy.
Hi
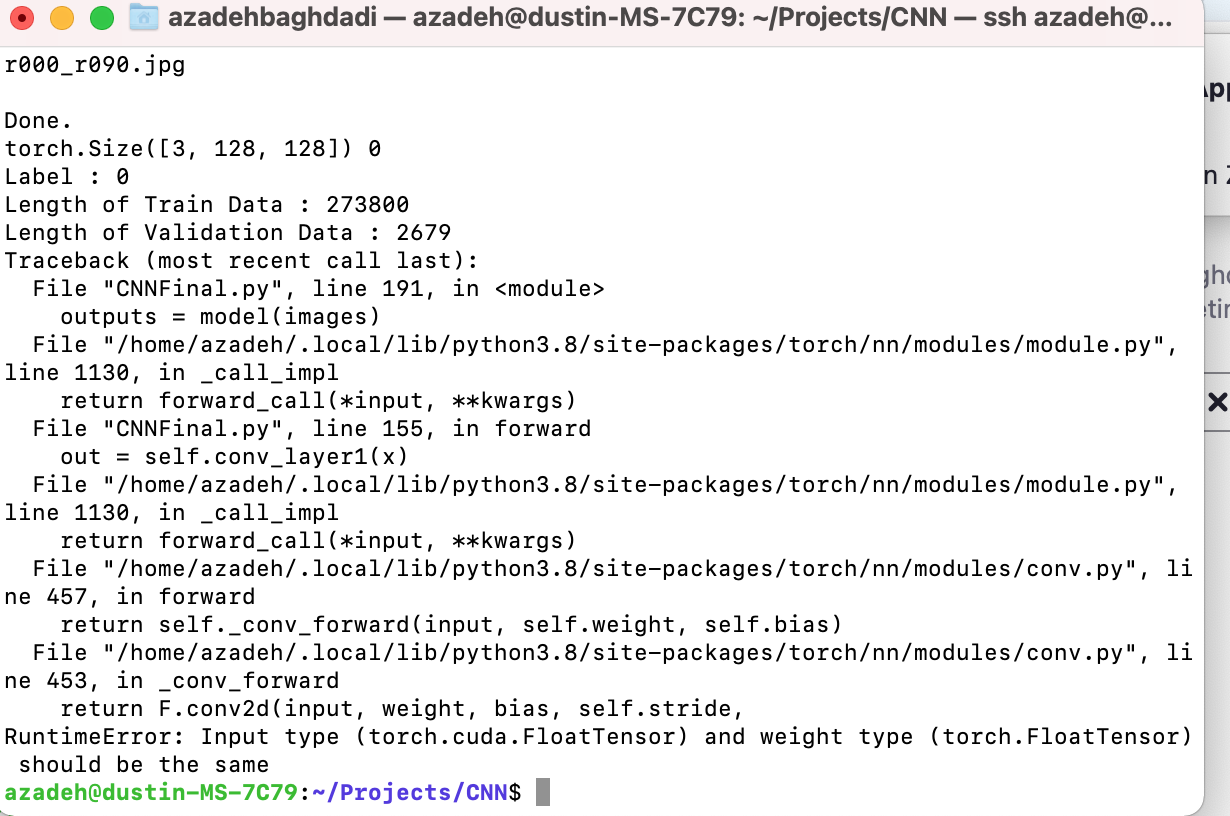
I have a code and when I run it on the GPU, I receive same error. I tried to solve it with the same solution, while it did not. Both data and code are on the GPU also.
I write below line:
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
And it is the code that has error in training step:
Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
it is the training step: #trainning
for epoch in range(num_epochs):
# Load in the data in batches using the train_loader object
for i, (images, labels) in enumerate(train_dl):
# Move tensors to the configured device
images = images.to(device)
labels = labels.to(device)
The code looks generally alright assuming you are also moving the model to the device.
Could you post the model definition as well as the input shapes so that I could try to debug it?
PS: you can post code snippets by wrapping them into three backticks ```, which makes debugging easier
self.conv_layer1 is still in the CPU, so check if the model.to(device) call moved the parameters to the GPU e.g. by printing the .device attribute of the weight.
Hi again,
How can I do this? I am new at python and CNN, is it possible let me know about the code line that I should write the .device attribute of the weight?