Hello,
I have a similar problem (link) and I created a discussion for it.
I was able to create a CustomDataset that return an image and a label (both tensor). Then I pass them to the Dataloader, but then, we I get the Image and Target from the Dataloader in the BackPropagation, the size is not right.
The CustomDataset is:
class CustomDataset(Dataset):
def __init__(self, csv_file, id_col, target_col, root_dir, sufix=None, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
id_col (string): csv id column name.
target_col (string): csv target column name.
sufix (string, optional): Optional sufix for samples.
transform (callable, optional): Optional transform to be applied on a sample.
"""
self.data = pd.read_csv(csv_file)
self.id = id_col
self.target = target_col
self.root = root_dir
self.sufix = sufix
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
# get the image name at the different idx
img_name = self.data.loc[idx, self.id]
# if there is not sufic, nothing happened. in this case sufix is '.jpg'
if self.sufix is not None:
img_name = img_name + self.sufix
# it opens the image of the img_name at the specific idx
image = Image.open(os.path.join(self.root, img_name))
# if there is not transform nothing happens, here we defined below two transforms for train and for test
if self.transform is not None:
image = self.transform(image)
# define the label based on the idx
#label = self.data.loc[idx, self.target].values
#label = torch.from_numpy(label.astype(np.int8))
#label = label.squeeze(-1)
#Test second option
label_test = self.data.iloc[idx, 1:5].values.astype('float32')
return image, label_test
and the data_transforms and params are as below
data_transforms = {
'train': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
}
params = {
'id_col': 'image_id',
'target_col': ['healthy', 'multiple_diseases', 'rust', 'scab'],
'sufix': '.jpg',
'transform': data_transforms['train']
}
train_dataset = CustomDataset(csv_file=data_dir+'train.csv', root_dir=data_dir+'images', **params)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
As you see, the target is four categories where the image is identified. Like this
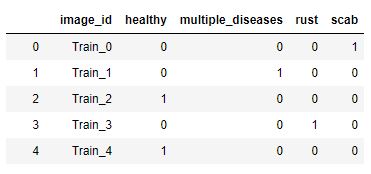
My issue is when I do the backpropagation with the dataloader, I have the wrong target size ([16]) instead of ([4]).
The training is like this
def train2(n_epochs, loaders, model, optimizer, criterion):
"""returns trained model"""
# initialize tracker for minimum validation loss
valid_loss_min = np.Inf
for epoch in range(1, n_epochs+1):
# initialize variables to monitor training and validation loss
train_loss = 0.0
valid_loss = 0.0
###################
# train the model #
###################
model.train()
for idx, (data, target) in enumerate(loaders):
## find the loss and update the model parameters accordingly
## record the average training loss, using something like
## train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data - train_loss))
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output = model(data)
print(idx)
target.view(-1)
print(target.shape)
target = target.long()
loss = criterion(output, target)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
#update training loss
train_loss += loss.item()*data.size(0)
# calculate average losses
train_loss = train_loss/len(loaders.sampler)
# print training/validation statistics
print('Epoch: {} \tTraining Loss: {:.6f} \tValidation Loss: {:.6f}'.format(
epoch,
train_loss,
))
# return trained model
return model
This is the link to the github so I can track my progress so you can have the full picture.
Any ideas, suggestions?