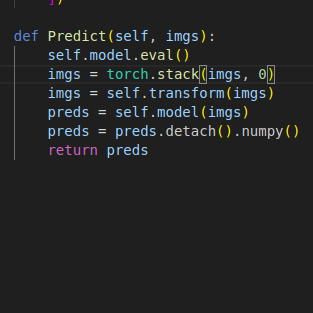
Hey there I am new to PyTorch. I have a inference code that predicts and classify images. I can predict and classify images one by one, can anyone please help me to classify all the images of a folder in a batch.
Usually a device is where you do your computations, for example if you use a GPU your device will be something like cuda:0 or just 0.
So what torch.cuda.current_device() does is to return the identifier of which GPU is currently being used. This can be really helpful for systems with multiple GPUs.
I guess the answer would depend on your network and input, but according to some tests I ran, time is the same for batch or single image. So yes, it reduces the per-image inference time.
import torch
single_image = torch.rand(1,3,300,300).cuda()
multiple_images = torch.rand(8,3,300,300).cuda()
network = torch.hub.load('pytorch/vision:v0.9.0', 'resnet50').cuda().eval()
with torch.no_grad():
%timeit network(single_image)
#33.2 ms ± 123 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit network(multiple_images)
#33.2 ms ± 399 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Running multiple image inference depends on your application and hardware. For example:
If you are training, the bigger the batch size the better. Because it will allow you to have a better gradient update, and in the end a faster training time. Remember that inference is not all the computation you perform when executing your model. Things like pre and post-processing also take time, and if you can do these steps at the same time for many images your computation time will be reduced!
If you are using a live system, you don’t want to wait and have many images to do inference in all of them at once. Usually, you want to do inference on the latest available image (batch of 1). Even though the computation time per image is reduced, it may be too slow the overhead caused by the rest of the system, making single image inference the best option.
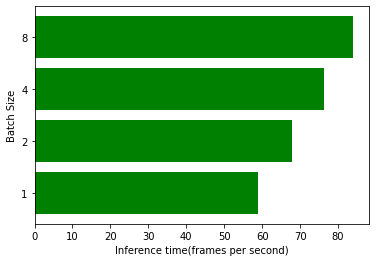
yes you are right and I guess the difference in inference time is quite large when I just using CPU otherwise in the case of GPU, I guess only a little difference in inference time when I did the batch inference. Here is the graph for Resnet-18 inference using GPU, on 256 images.

 worked like a charm
worked like a charm