I am new to PyTorch and I am trying to load the MoCo model in order to use it.
In the following site: https://github.com/facebookresearch/moco I have found the code and also, I downloaded the pre-trained model (‘moco_v2_800ep_pretrain.pth.tar’) which is a state_dict with the model’s wheights.
I know that in order to use a model I need to create a model instance first and then load the state_dict.
My problem is that I can not create an instance model of MoCo. I saw the code on GiHub and I end up with the following code:
If I understand it right, first I need to load the Resnet50 model and then load the pre-trained weights to this model.
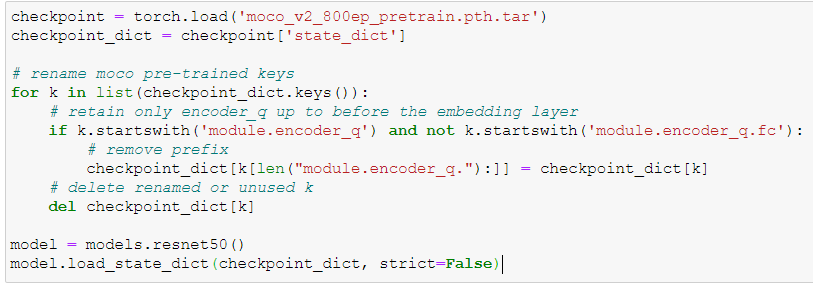
So, according to your answer and with the code that you mentioned, with the following code I have the Resnet50 model with the MoCo pre-trained weights:
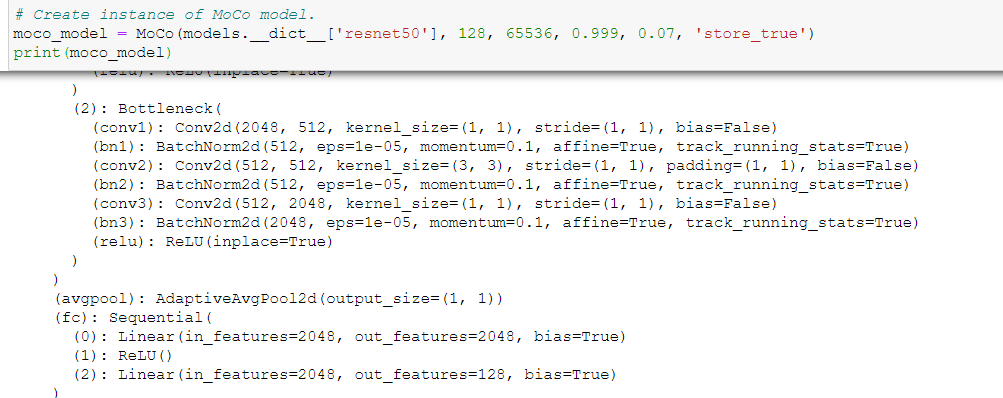
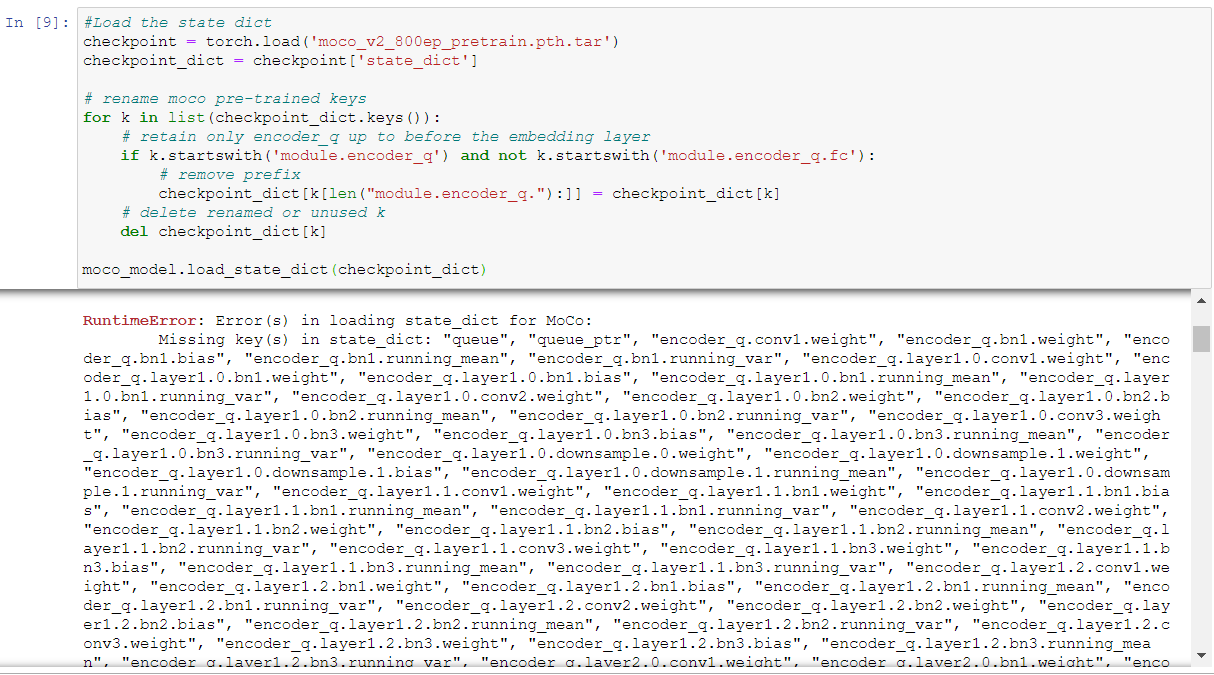
Based on the above and after I check again on the paper, I realised that MoCo model has an output vector of 128D, so I am trying to load this specific model right now, because the model on the previous posts has an output vector of 1000D.
They only released the weights for the ResNet50 layers not the entire MoCo model. You’d have to contact the authors if you want those parameters. What’s your goal? Are you trying to fine-tune the pre-trained weights?
for k in list(state_dict.keys()):
# retain only encoder_q up to before the embedding layer
if k.startswith('module.encoder_q') and not k.startswith('module.encoder_q.fc'):
# remove prefix
k_no_prefix = k[len("module."):]
state_dict[k_no_prefix] = state_dict[k] # leave encoder_q in the param name
# copy state from the query encoder into a new parameter for the key encoder
state_dict[k_no_prefix.replace('encoder_q', 'encoder_k')] = state_dict[k]
del state_dict[k]
msg = moco_model.load_state_dict(state_dict, strict=False)
This should give you the MoCo model with initialized query and key encoders (their parameters are copies of each other to begin with). The MLP and queue will still be randomly initialized; you’ll have to train them on your dataset.