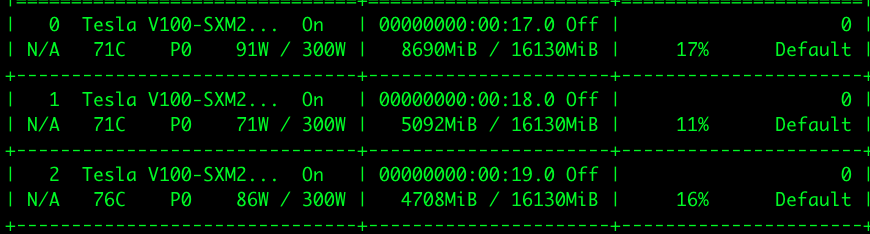
If I remember correctly, the default setting of DataParallel tries to split the minibatch equally into smaller patches, but in NLP model, the minibatches are sorted by length in decreasing order, that makes the first GPU under heavier load. Ideally if we can explicitly controls the splitted batch size so that the total number of tokens are roughly balanced. Is there anyway to do this efficiently?
Hey,
If you are using Dataset and DataLoader, if you set the argument shuffle = True in DataLoader(), it will automatically shuffle the examples within a batch.