Hi everyone, in my implementation of my model, which consists of several resnet-block-like blocks and arbitrary skip connections from previous blocks. Just like this:
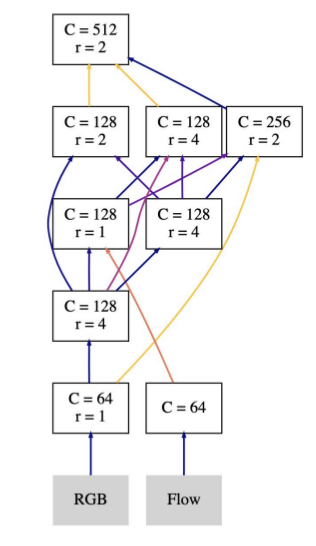
My problem is, although the model parameters itself doesn’t take a lot of the GPU memory(about 2000MB), the intermedia memory can be very large(total can be around 16G with input of size [2,5,32,224,224]) which always caused OOM. My ‘forward’ inplementation is like this.
def forward(self, x):
b, c, t, d1, d2 = x.size()
x = x.permute(0, 2, 1, 3, 4).contiguous()
x = x.view(b *t, c, d1, d2)
self.output_data[-1] = x[:, 0:3, :, :]
self.output_data[-2] = x[:, 3:5, :, :]
for idx, node in enumerate(self.net):
self._prepare_input(idx)
self.output_data[idx] = node(self.input_data[idx])
del self.input_data[idx]
torch.cuda.empty_cache()
return self.output_data[self.num_node - 1]
def _prepare_input(self, node_idx):
sum_tensor = None
for i, input_idx in enumerate(self.node_list[node_idx]["input"]):
input_data = self.output_data[input_idx]
if input_idx != -1 and input_idx != -2:
#logger.info("DEBUG4: data from {} to {}".format(input_idx, node_idx))
adjust_model = self.adjust_modules[node_idx][i]
input_data = adjust_model(input_data)
if node_idx != self.num_node - 1:
input_data = input_data * torch.sigmoid(self.arch_weight[node_idx][input_idx])
if node_idx == self.num_node -1:
if sum_tensor is None:
sum_tensor = input_data
else:
sum_tensor = torch.cat((sum_tensor, input_data), 1) # Concat along dim: Channel
else:
if sum_tensor is None:
sum_tensor = input_data
else:
sum_tensor += input_data
self.input_data[node_idx] = sum_tensor
My nn.Module has two actual sub-module, one named self.net which is a ModuleList, storing all the nodes. And another called self.adjust_nodes which is a 2-D ModuleList, storing the corresponding bottleneck and pooling layers to adjust the tensor size from “i”-th node to “j”-th node.
As you can see, I use two dicts: self.input_data adn self.output_data to store the intermedia data tensors. The inputs to each nodes can have different tensor size, therefore I transform all of them into same size by some pooling and bottleneck in the _prepare_input function. I store the output of each node for further use if it is directed to the blocks behind.
Although I try to use del and empty_cache to delete the input tensor which has been used and will never be used again, the memory still keeps as high as always.
Is there other more sophisticated way to implement such model, or is there any other way to manipulate the memory freely? Thanks!