hi, I have this data where for each sample there is a image list [img1, img2, img3, …]. For each image, the shape is different, and for each sample the number of images also varies.
I could come up with some conv net where different sized image could be reduce to a fix length representation (by adaptive pooling). But the only solution for number of images i can think of is just sample them to be the same.
Could anyone give me some idea that uses some neural network instead of sampling to deal with this issue?
A few approaches that are often used would be to crop the image, by clipping off extraneous parts or resizing an image by squeezing or extending the sides.
It would often be best to choose a size that would work best for the output. Other, more interesting approaches, would be to take glances of the image using an RNN, which would allow you to make the input any size [1, 2, 3]. A more naive approach would be to add 0 padding to all of the extra space in the image; however, this would take up a lot of memory.
Thank you for your reply! it is very useful to see that so many method can be done on variable size images. However, I still have the issue that within each sample I get variable number of images. So I can crop/resize or do some fancy stuff to make each image same size, I still can not make the number of images per sample the same.
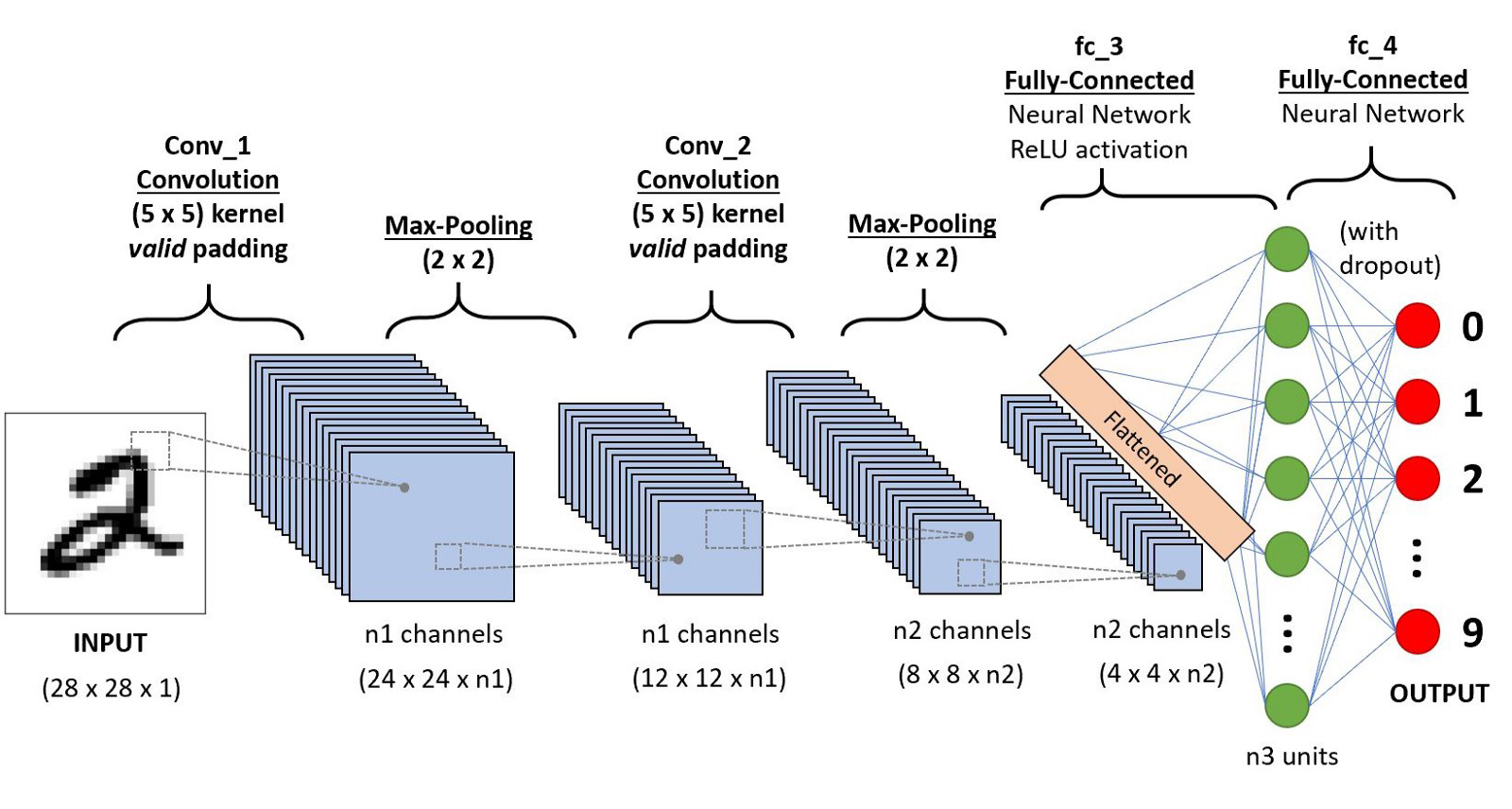
. Not entirely sure I understand what you mean. I assume your NN/CNN inputs a single image, like what is shown in the following graphic. Of course, this operation can be parallelized, but this is the general structure.
But I’m confused what you mean by making the number of samples the same. Are you using samples to refer to the number of images per mini-batch, the number of images per training set, or something along those lines?
hi, what i meant is that my data is like sample -> target, where each sample is a series of images. So in this case we are not predicting one target for one image, but one target for a series of images.
haha. I think @yolle103 is referring to something like training on “videos”. Each video is of a different duration and so different number of frames or “images” and he predicts one output for one video input. @yolle103, you could look at some approaches in lip reading research or similar “video” to target problems.
As an approach that I think is okay to start off with: You resize your “images” to fit a certain fixed shape and then sort your “videos” from shortest to longest. After this, pad the ends of the “video” training examples to the largest in the batch. Due to the sorting, this then would not be too much of an extra compute for your GPU. Your maximum video length per batch, though, will be different. For this, after passing it through a initial CNN feature extractor, you must use a sequence modelling model, like an RNN: GRU, LSTM. Now you have a nice, fixed size, output for each “video” to further train using!
[Of course, there are drawbacks to this “sorting” trick, for example, remember to set shuffling of your data to False everywhere to avoid massive compute overheads. A way to overcome this as a drawback is to call it “curriculum learning” and pass it off as helping your model to converge faster ]
As an example: Videos have been sorted from smallest to largest. Each frame has been reshaped to size 3x80x80 (3channels). batch size is 4 and video 1, video 2, video 3, video 4 are in one batch and are of sizes. 24x3x80x80, 26x3x80x80, 28x3x80x80, 29x3x80x80. Add zero frames of size 3x80x80 to video 1, 2 and 3 and so you get a batch to train of final size 4x29x3x80x80. Then use CNNs and finally RNNs because this number “29” will vary across your batches.

 ]
]