Hi,
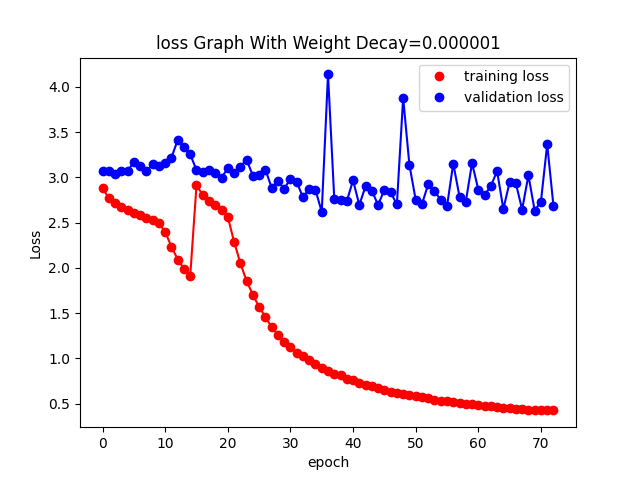
I am trying to train a model for Handwritten text recognition task using encoder-decoder with attention. The loss of validtion is not decressing after reaching some value and train loss is getting decreseing and there is huge gap between them.
I have tried Dropout 0.5 after CNN fc layer and at the input of decoder. A Different weight decay from 0.1 to 0.000001 and also data augumenation have been applied.
I am using optim.Adam and nn.CrossEntropyLoss. My training exapmles are 8161 and validtion samples are 900.
Can anyone help me what is going wrong ?
Here is the loss:
here is the Encoder:
class Encoder(nn.Module):
def init(self,height, width, enc_hid_dim, dec_hid_dim, dropout):
super().init()
self.height= height
self.enc_hid_dim=enc_hid_dim
self.width=width
self.num_layers=1
self.layer0 = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=(3,3),stride =(1,1), padding=1),
nn.ReLU(),
nn.BatchNorm2d(8),
nn.MaxPool2d(2,2),
)
self.layer1 = nn.Sequential(
nn.Conv2d(8, 32, kernel_size=(3,3),stride =(1,1), padding=1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.MaxPool2d(2,2),
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(3,3),stride =(1,1), padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(2,2)
)
self.rnn=nn.LSTM(self.height//8*64, self.enc_hid_dim, num_layers= self.num_layers, bidirectional=True)
self.fc = nn.Linear(self.enc_hid_dim * 2, dec_hid_dim)
self.dropout_layer = nn.Dropout(dropout)
def forward(self, src, in_data_len, train):
batch_size = src.shape[0]
out = self.layer0(src)
out = self.layer1(out)
out = self.layer2(out)
if train:
out = self.dropout_layer(out) # torch.Size([batch, channel, h, w])
out = out.permute(3, 0, 2, 1) # (width, batch, height, channels)
out.contiguous()
out = out.reshape(-1, batch_size, self.height//8*64) #(w,batch, (height, channels))
width = out.shape[0]
src_len = in_data_len.numpy()*(width/self.width)
src_len = src_len + 0.999 # in case of 0 length value from float to int
src_len = src_len.astype('int')
out = pack_padded_sequence(out, src_len.tolist(), batch_first=False)
outputs, hidden_out = self.rnn(out)
hidden=hidden_out[0]
cell=hidden_out[1]
# output: t, b, f*2 hidden: 2, b, f
outputs, output_len = pad_packed_sequence(outputs, batch_first=False)
#outputs = [src len, batch size, hid dim * num directions]
#hidden = [n layers * num directions, batch size, hid dim]
#hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
#outputs are always from the last layer
#hidden [-2, :, : ] is the last of the forwards RNN
#hidden [-1, :, : ] is the last of the backwards RNN
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))
cell = torch.tanh(self.fc(torch.cat((cell[-2,:,:], cell[-1,:,:]), dim = 1)))
return outputs, hidden, cell