I’m using PyTorch to train a model for image segmentation and I need to use GPU shared memory
(simply because GPU VRAM is not enough for training the model in the laptops I have available).
I have two laptops available and I’m training the model within Conda environment in Windows, so I expect all
(or most of) settings to be identical in both computers. In one laptop, training performs successfully, as it starts using GPU shared memory once GPU dedicated memory saturates (figure below). However, in the other laptop, when GPU
dedicated memory saturates, it just gives runtime error rather than using shared memory (the other figure). The error message is as follows:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 8.00 GiB total capacity; 7.22 GiB already allocated; 0 bytes free; 7.25 GiB reserved in total by PyTorch)
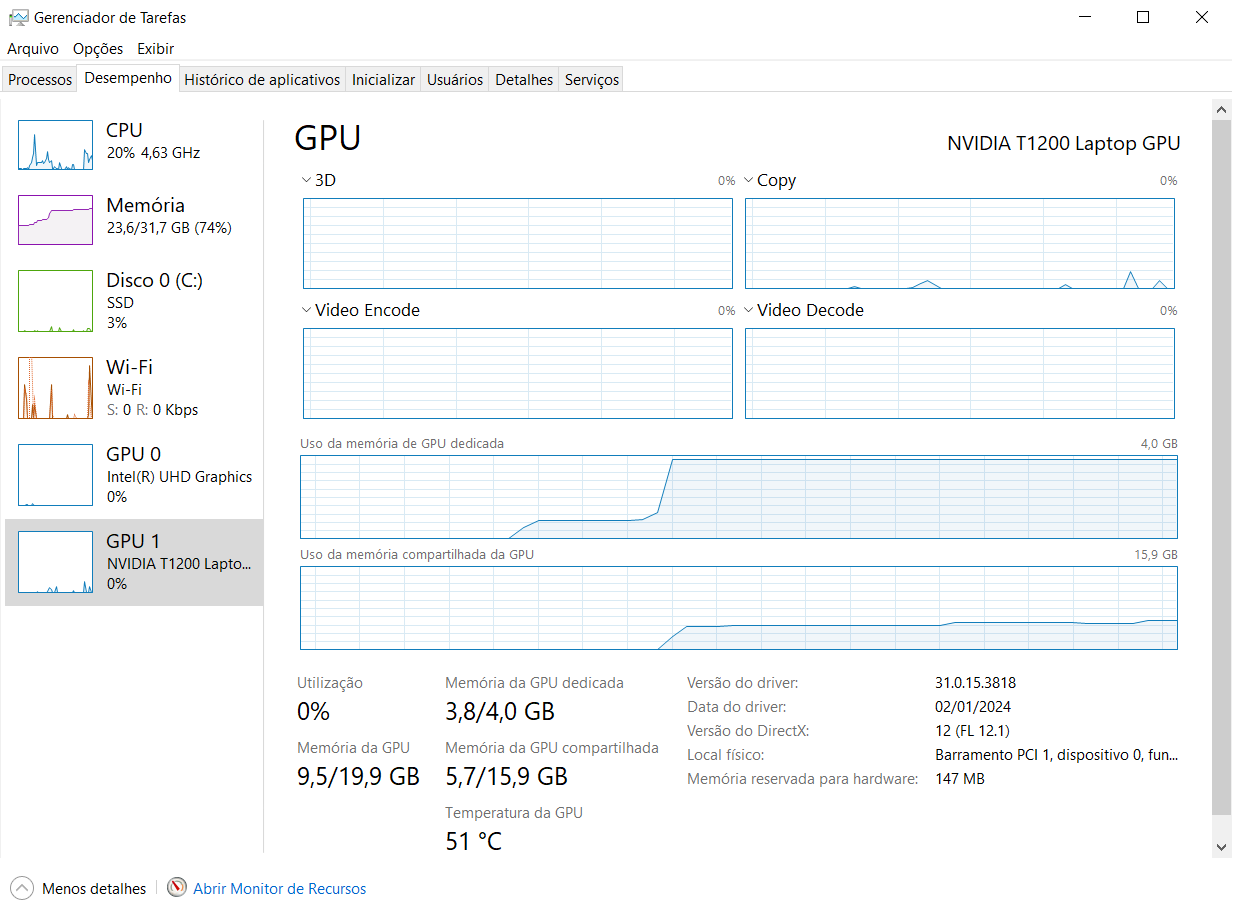

Details:
- laptop that succeeds: Windows 10, NVIDIA T1200 Laptop GPU
- laptop that fails: Windows 11, NVIDIA GeForce RTX 4060 Laptop GPU
In both cases, I’m running the exact same code, and Python, CUDA, CuDNN and Torch are installed with the same versions, as it is installed via Conda:
conda create -n env_name python=3.9.12
pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
Does someone has any clue of what could be blocking GPU of using shared memory? Could it be some PyTorch settings? Or could this be due to GPU settings or something?